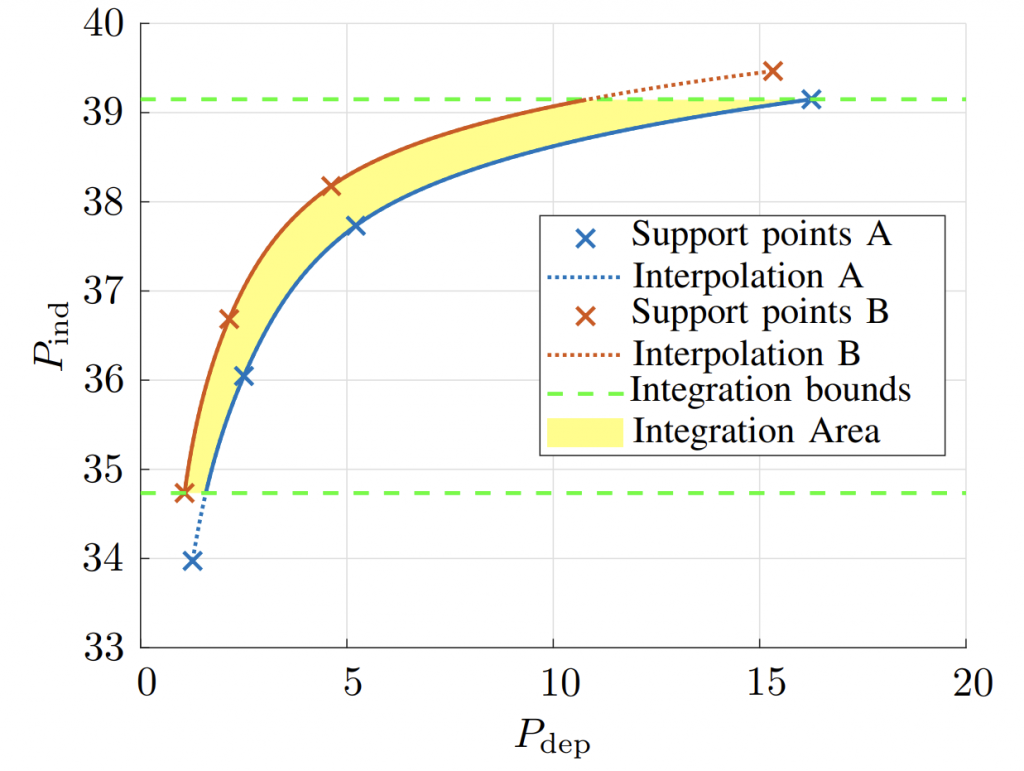
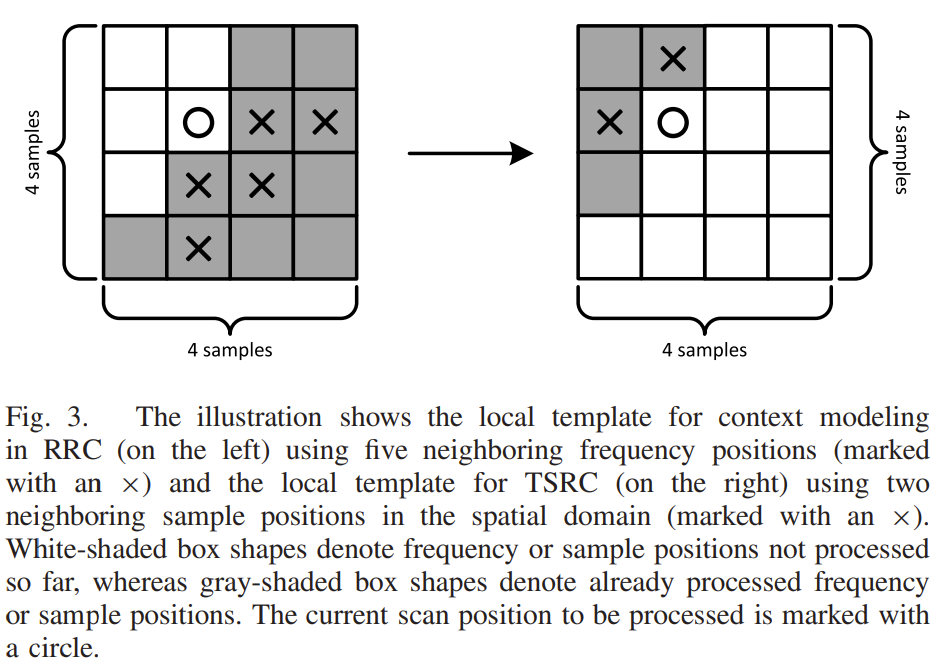
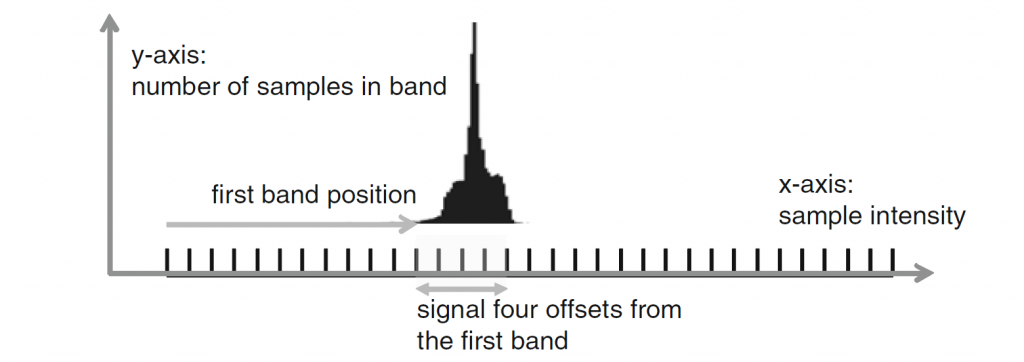
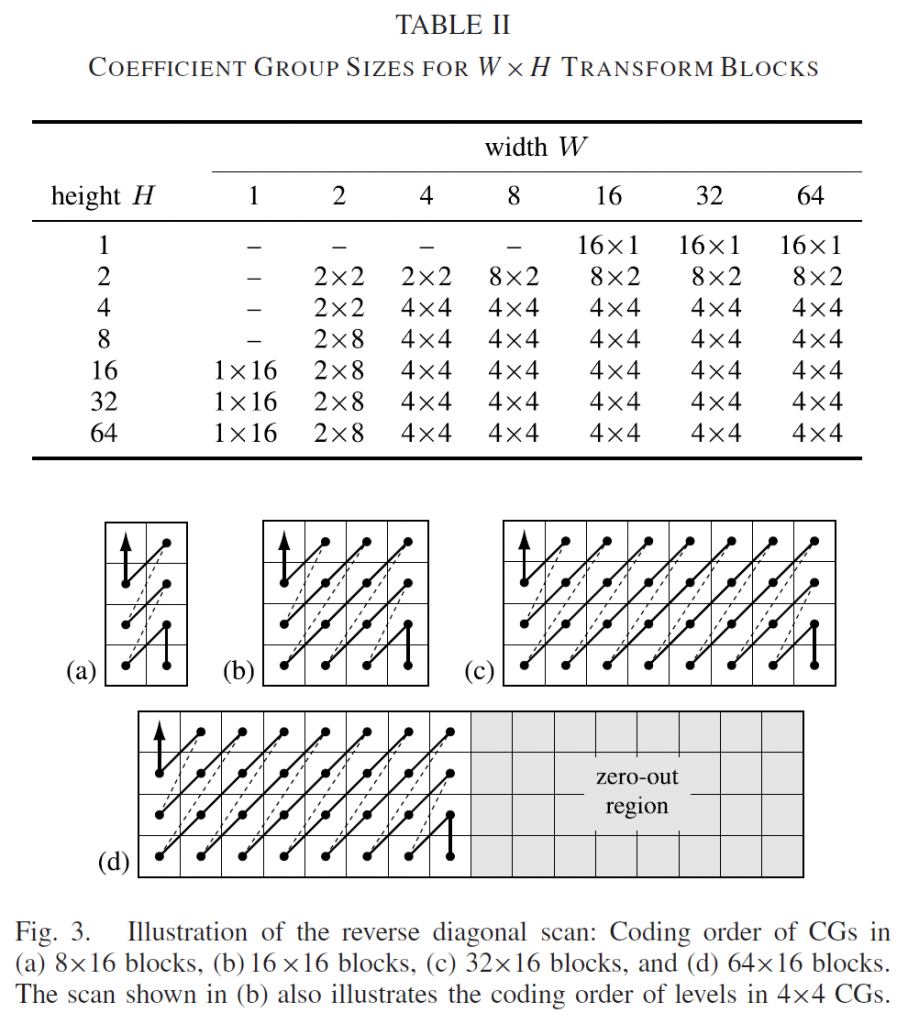
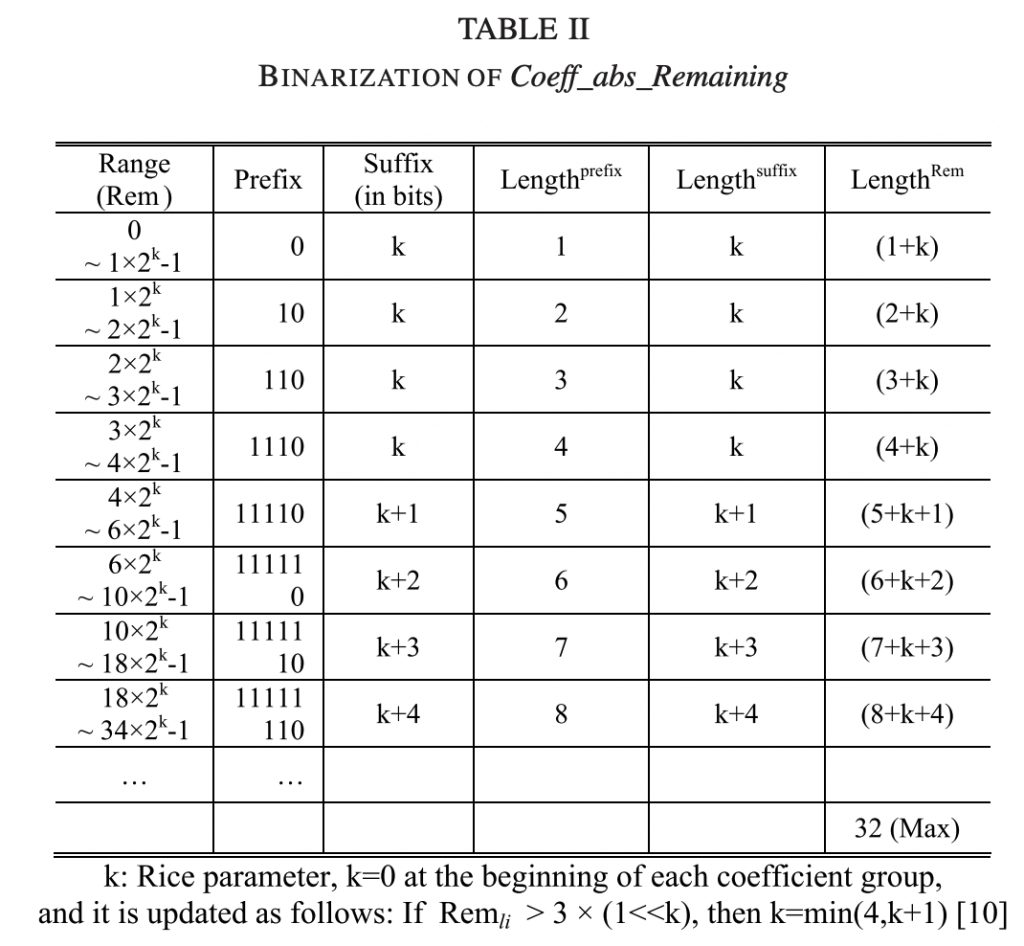
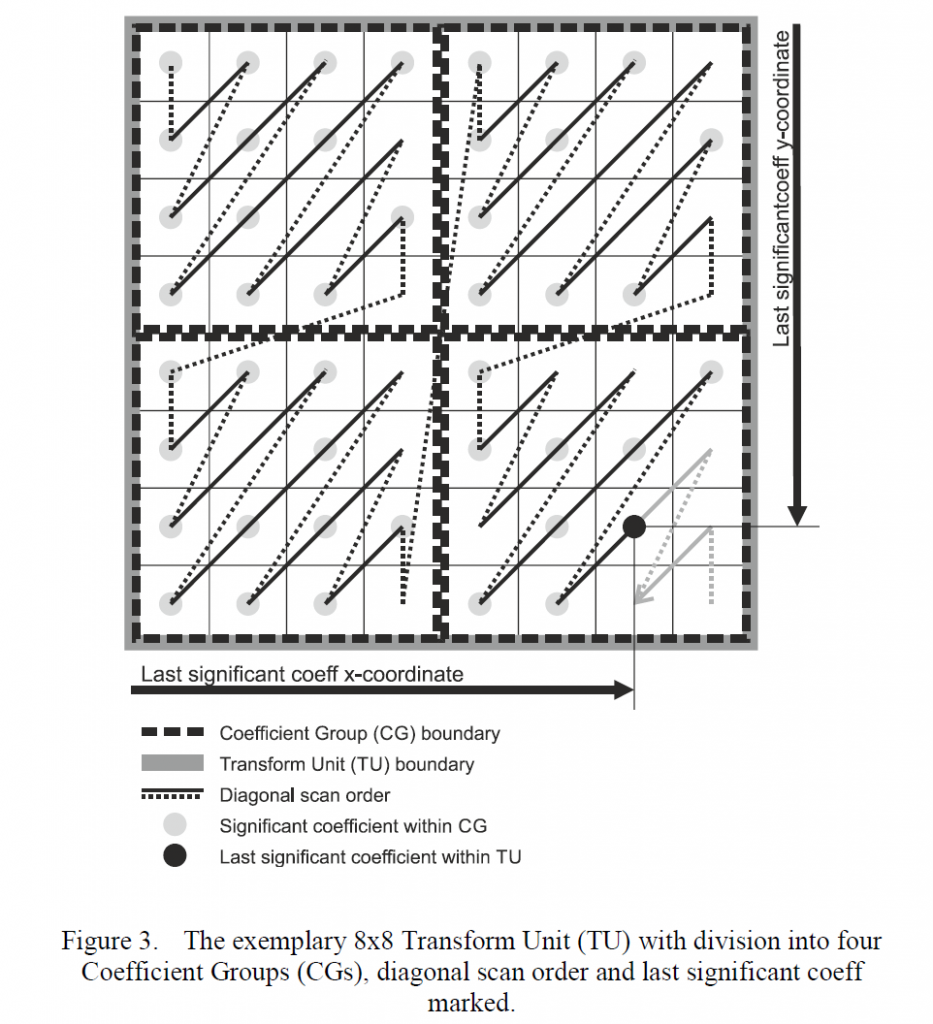
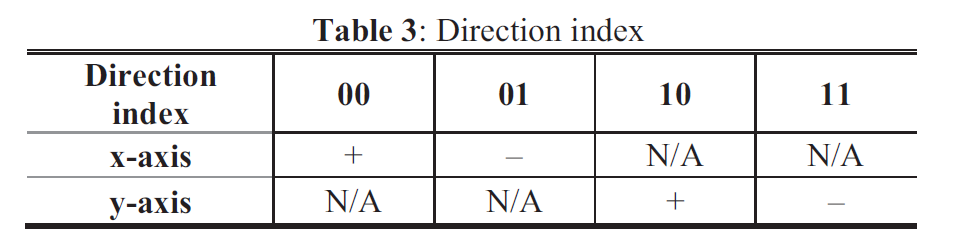
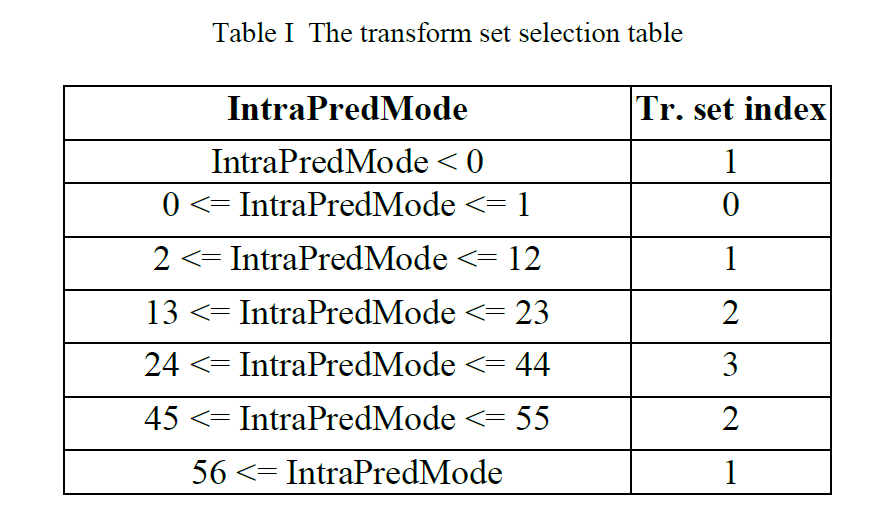
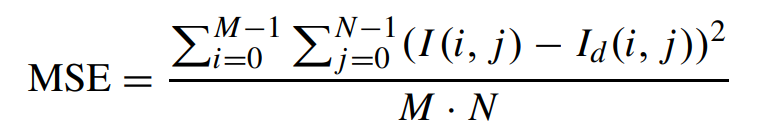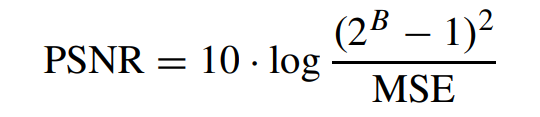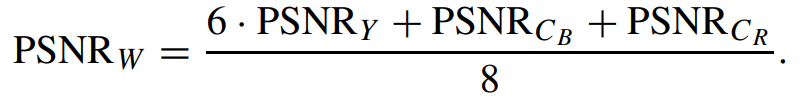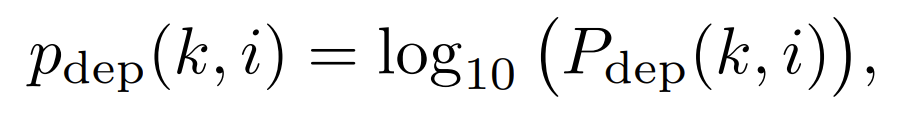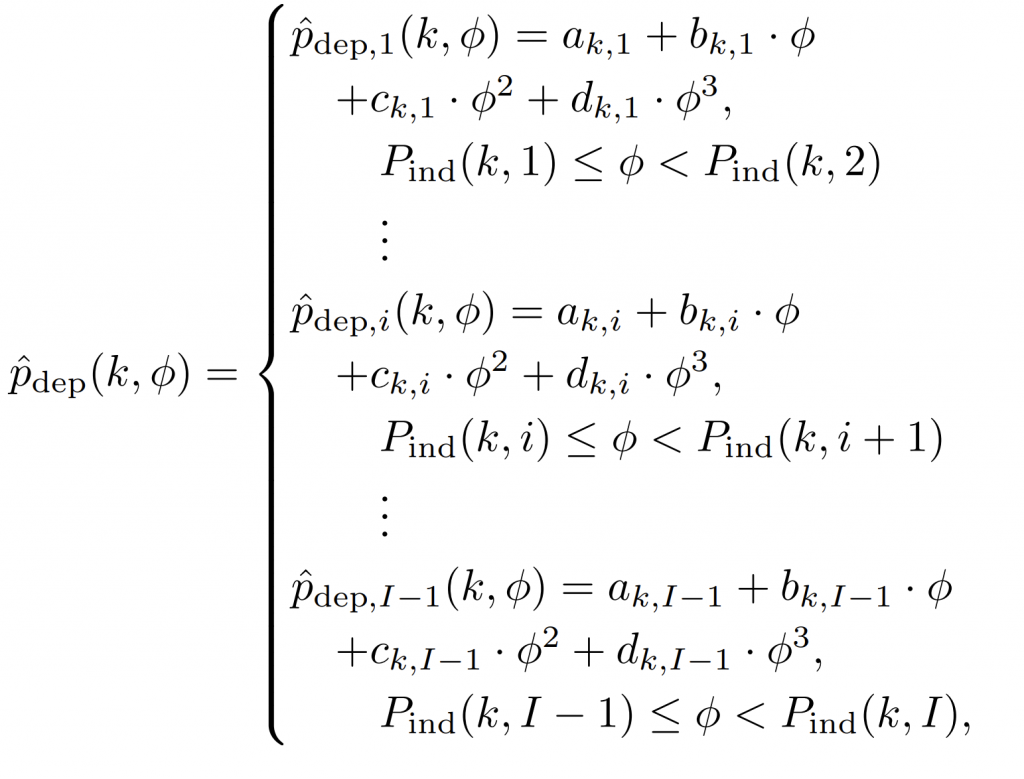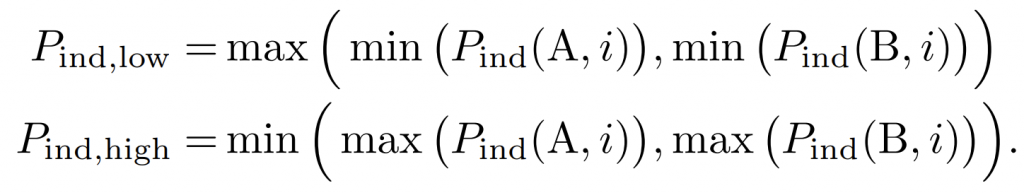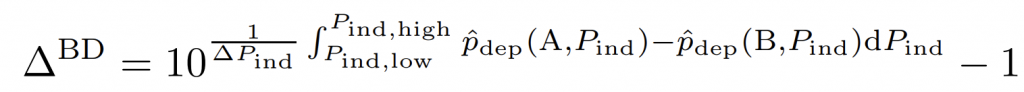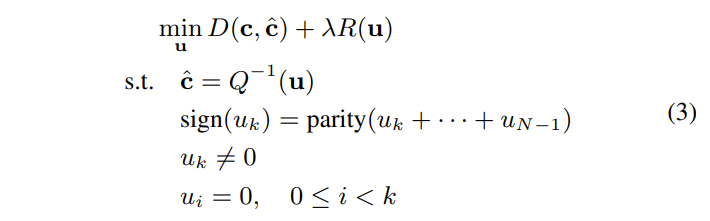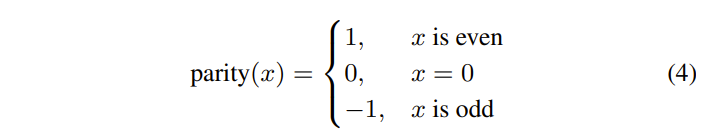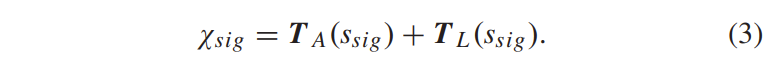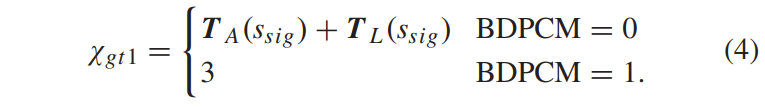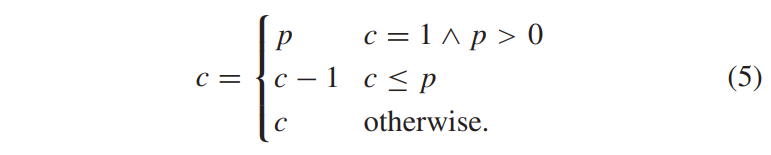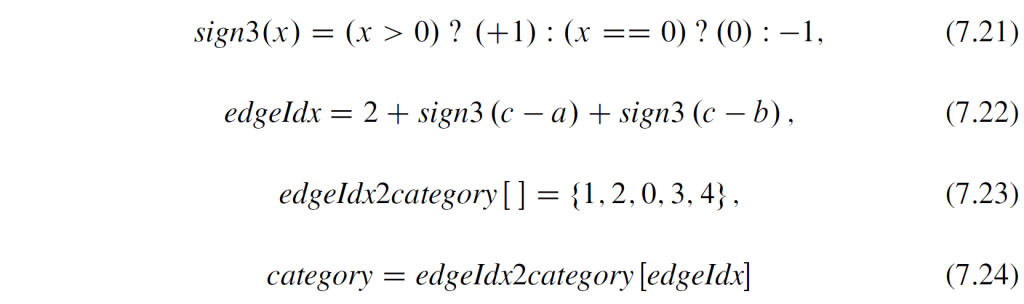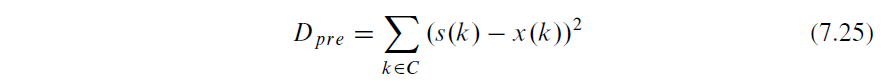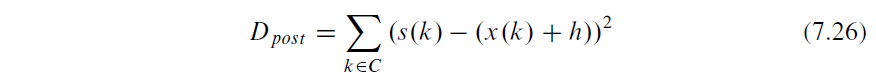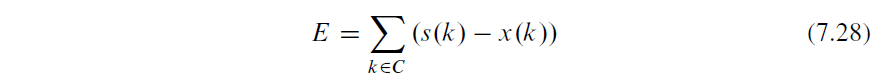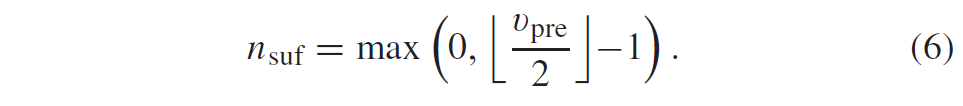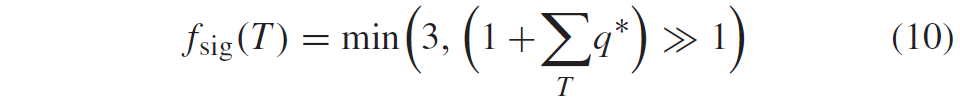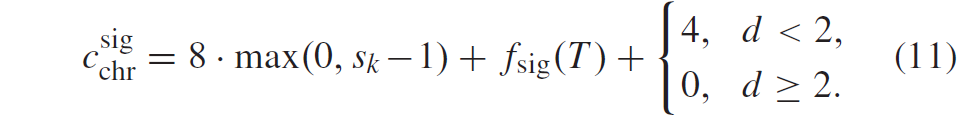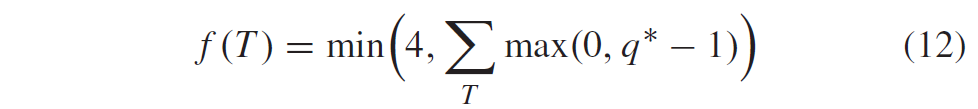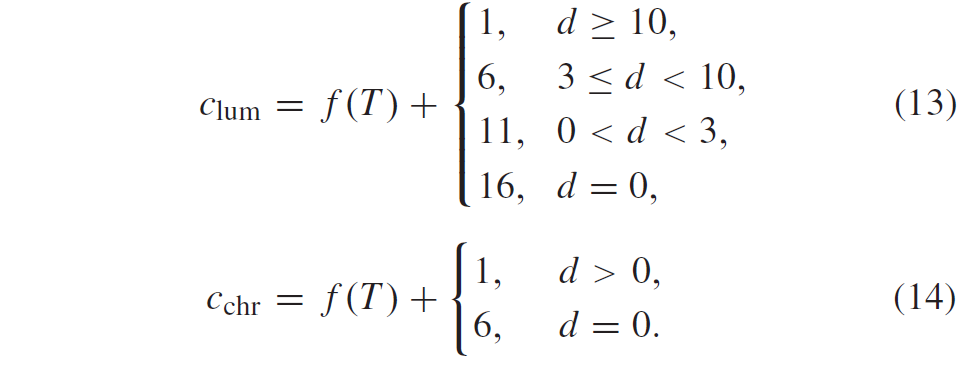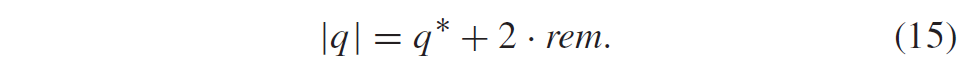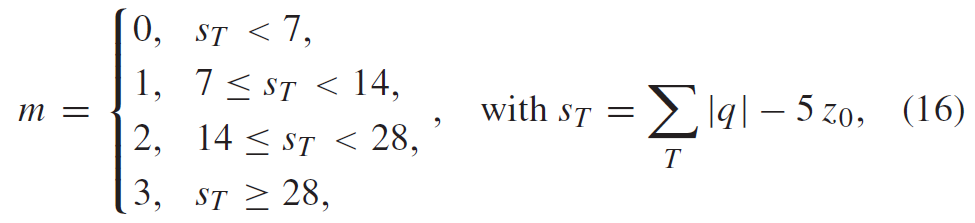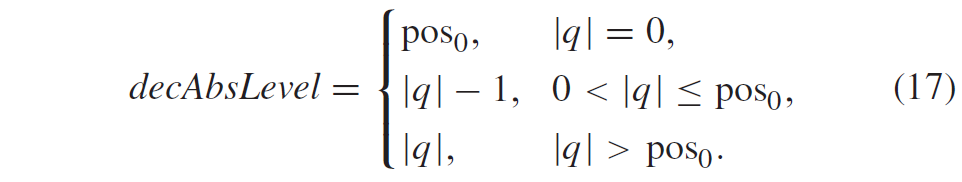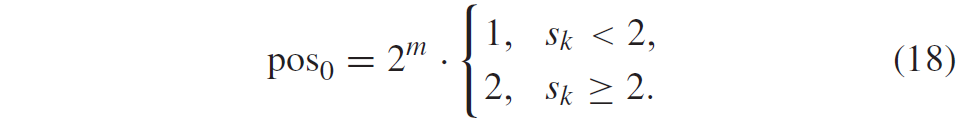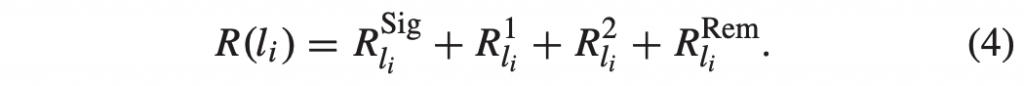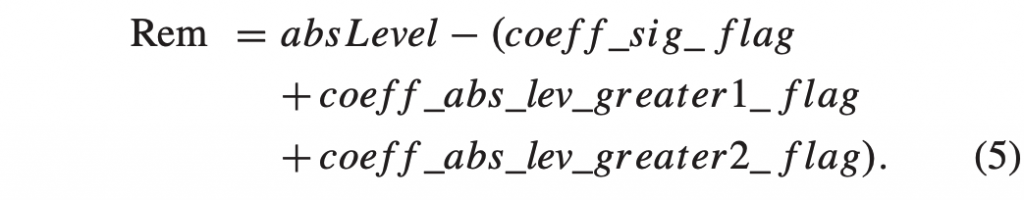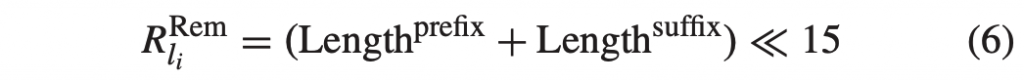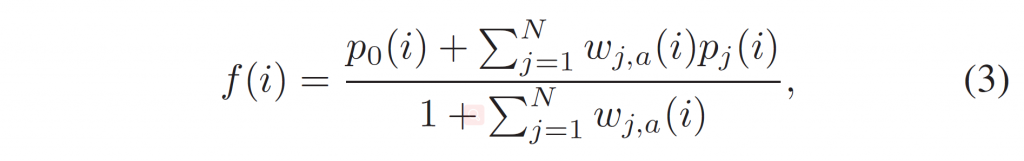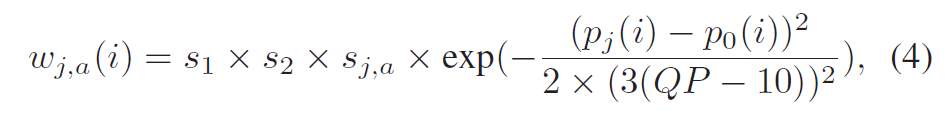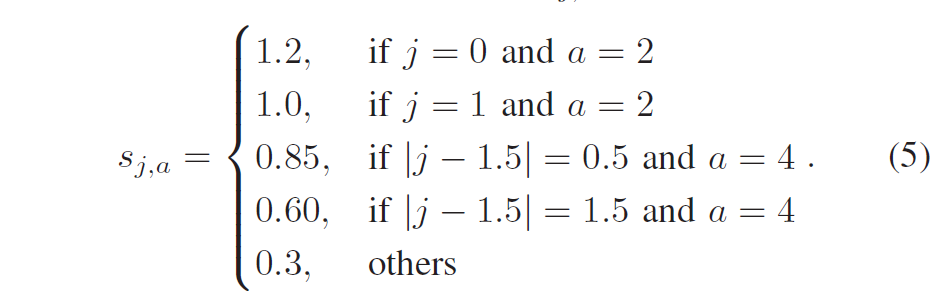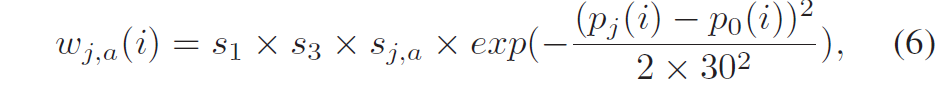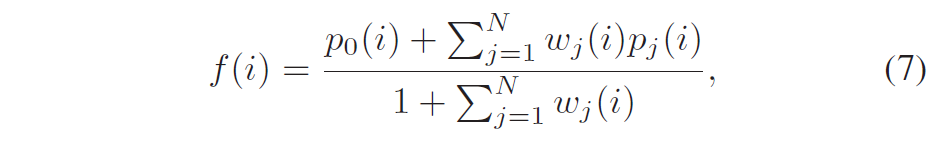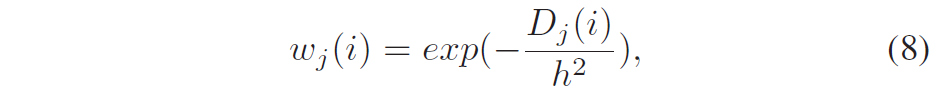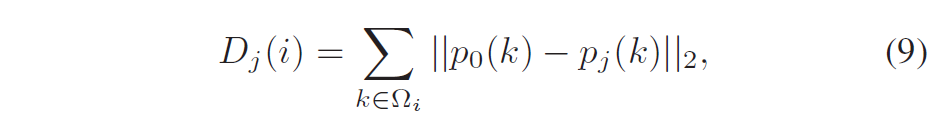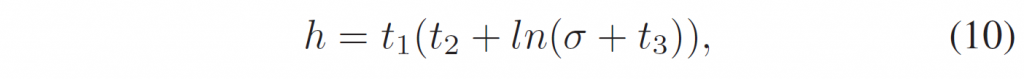积分范围 ΔPind = Pind,high − Pind,low。 它描述了使用编码器 k = A 相对于参考编码器 k = B 进行编码时在积分范围内的相对比特率差异。请注意,平均差(即积分)是在对数域中计算的 ,与计算非对数域中的平均差异相比,它强调小差异并减少大差异的影响。 因此,BD 值可以解释为在对数域中平均的平均相对差值。
[1] M. Karczewicz, Y. Ye, I. Chong, “Rate Distortion Optimized Quantization”, ITU-T SG 16/Q 6 VCEG, document: VCEG-AH21, Jan. 2008. [2] J. Sole, R. Joshi, N. Ngyuen, T. Ji, M. Karczewicz, G. Clare, F. Henry, A. Duenas, “Transform Coefficient Coding in HEVC”, IEEE Transactions on Circuits and Systems for Video Technology, vol. 22, no. 12, pp. 1765-1777, Dec. 2012. [3]J. Sole et al., “Transform coefficient coding in HEVC,” IEEE Trans. Circuits Syst. Video Technol., vol. 22, no. 12, pp. 1765–1777, Dec. 2012. [4]V. Sze and M. Budagavi, “High throughput CABAC entropy coding in HEVC,” IEEE Trans. Circuits Syst. Video Technol., vol. 22, no. 12, pp. 1778–1791, Dec. 2012.
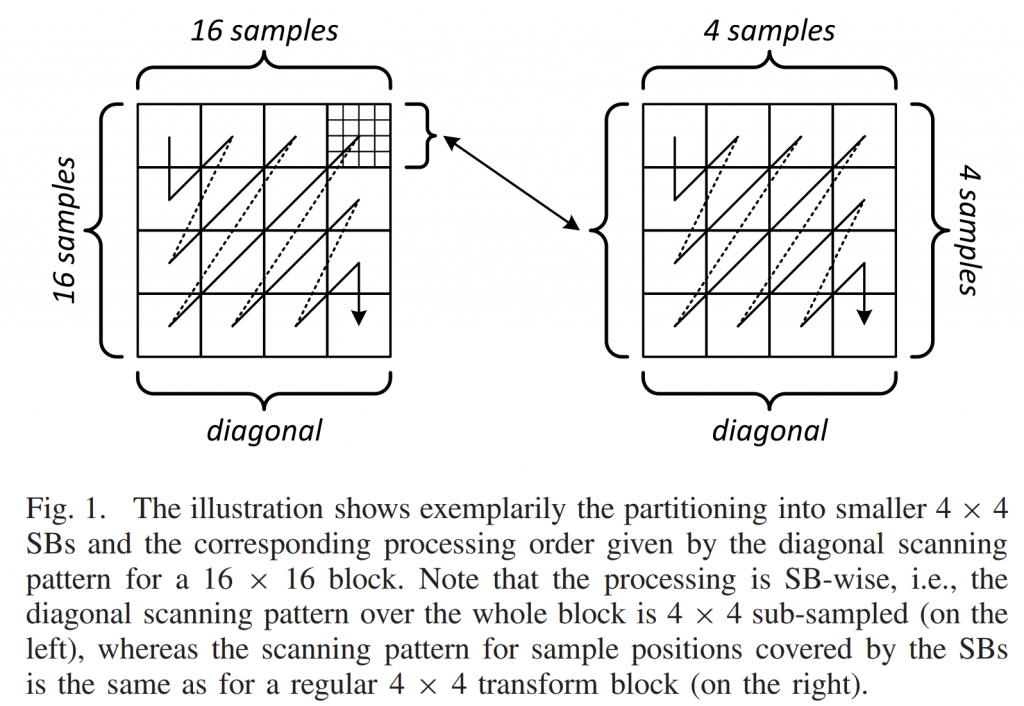
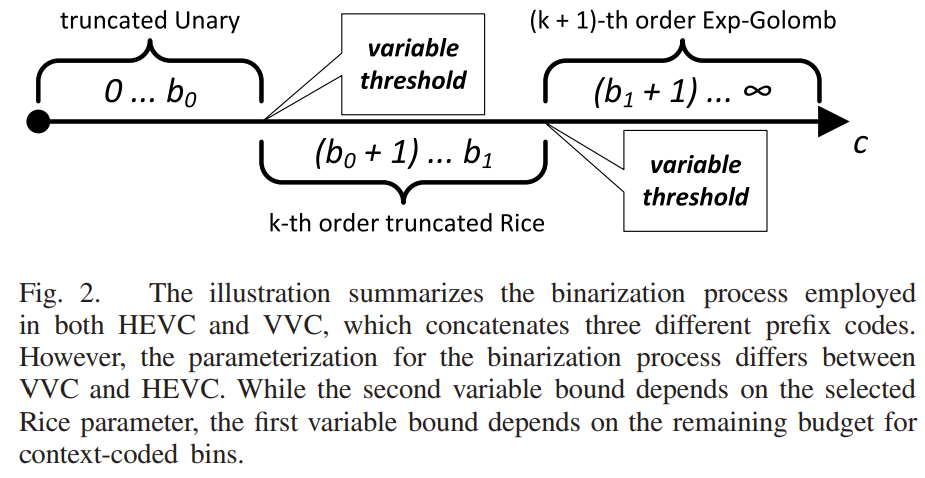
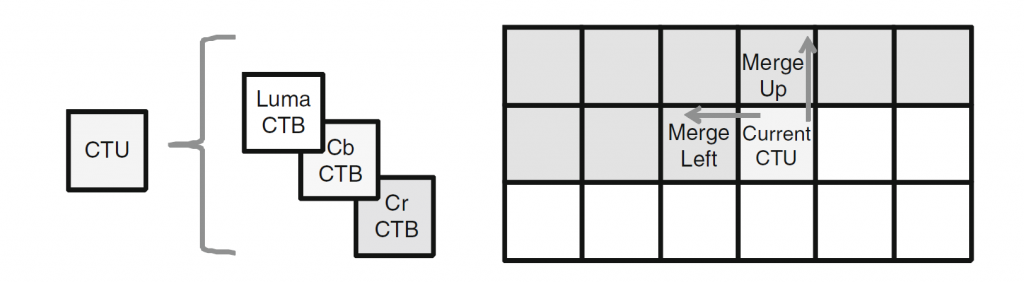
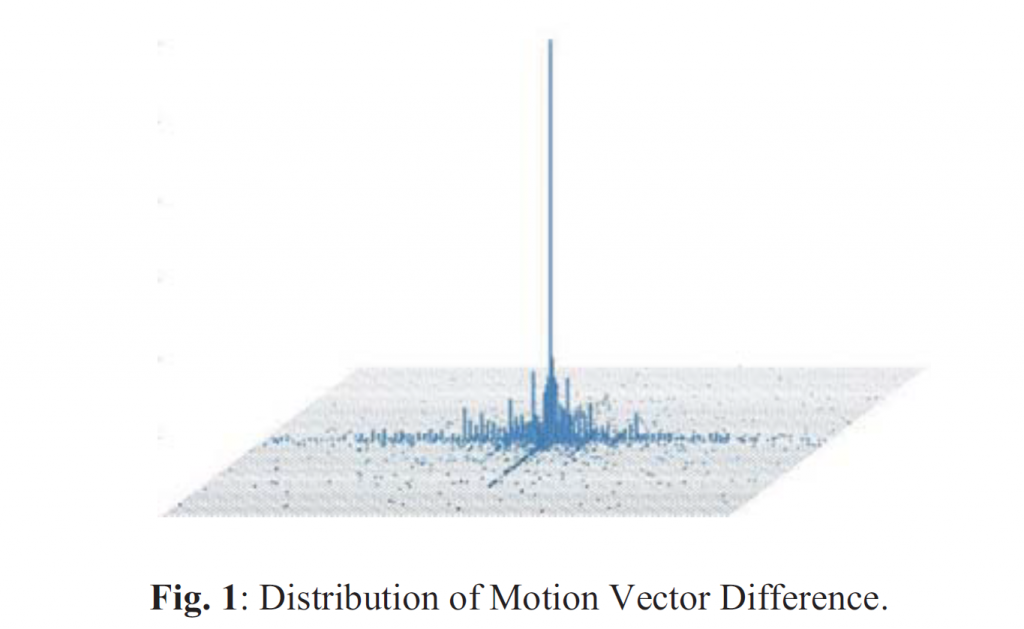
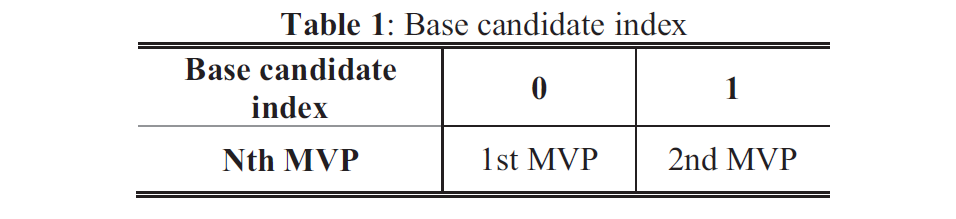
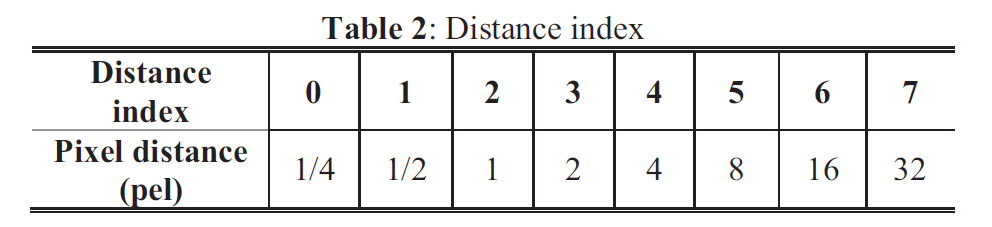
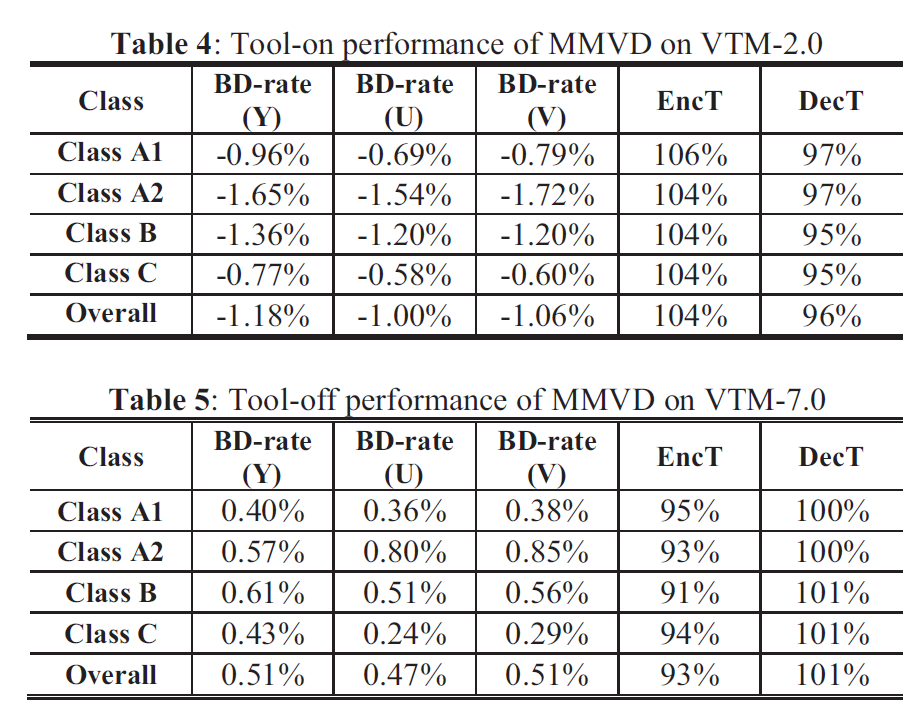
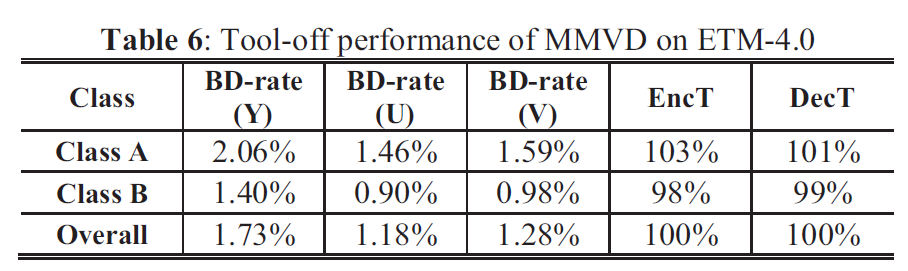
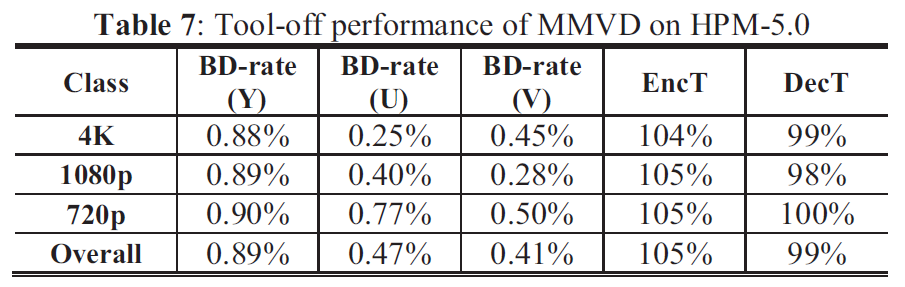
针对未来的视频编码标准,提出了一种新的运动矢量表达方法,即Merge mode with MVD(MMVD)。在先前的标准中,两种方法通常用于运动矢量表示。在第一种方法中,运动矢量从相邻块中导出,并直接用于运动补偿(HEVC中的Merge模式),在另一种方法中用MVP和MVD(自适应运动矢量预测;HEVC中为AMVP)表示运动矢量。Merge模式通过节省用于表示运动信息的比特而受益。AMVP表示更精确的运动信息,但它需要用信号发送MVD,这会消耗额外的比特。MMVD为运动矢量精度及其开销之间的权衡提供了折衷的解决方案。MMVD可以通过引入简化的运动向量表示来提高运动向量精度。结果表明,该方法提高了VVC的编码效率,平均节省了0.51%的BD码率。
[1] B. Bross, J. Chen, S. Liu, “Versatile Video Coding (Draft 6)”, document JVET-O2001, 15th Meeting: Gothenburg, SE, 3–12 July 2019.
[2] X. Zhao, A. Said, V. Seregin, M. Karczewicz, J. Chen, R. Joshi, “TU-level non-separable secondary transform”, Joint Video Exploration Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, Doc. JVET-B0059, 3rd Meeting
[3] M. Salehifar, M. Koo, J. Lim, S. Kim, “CE 6.2.6: Reduced Secondary Transform (RST)”, document JVET-K0099, Ljubljana, SI, Jul. 2018.
[4] M. Koo, M. Salehifar, J. Lim, S. Kim, “CE6: Reduced Secondary Transform (RST) (CE6-3.1)”, Joint Video Exploration Team (JVET) of ITU-T SG 16 WP 3 and ISO/IEC JTC1/SC 29/WG 11 JVET-N0193, 14th meeting, Geneva, CH, 19–27 March 2019.
[5] F. Bossen, J. Boyce, K. Suehring, X. Li and V. Seregin, “JVET common test conditions and software reference configurations for SDR video”, JVET-M1010, 13th JVET meeting, Marrakech, MA, 9–18 Jan. 2019.
[6] X. Zhao et al., “Description of Core Experiment 6 (CE6): Transforms and transform signalling”, JVET-M1026, 13th JVET meeting, Marrakech, MA, 9–18 Jan. 2019.
[1] Eric Dubois and Shaker Sabri. Noise reduction in image sequences using motion-compensated temporal filtering. IEEE Transactions on Communications, 32(7):826–831, 1984. [2] Jill M Boyce. Noise reduction of image sequences using adaptive motion compensated frame averaging. In In 1992 IEEE International Conference on Acoustics, Speech, and Signal Processing, volume 3, pages 461–464. IEEE, 1992. [3] Yaowu Xu. Inside webm technology: The vp8 alternate reference frame. http://blog.webmproject.org/2010/05/inside-webm-technologyvp8-alternate.html, 2010. [4] Eugen Wige, Peter Amon, Andreas Hutter, and Andre Kaup. In- ´ loop denoising of reference frames for lossless coding of noisy image sequences. In 2010 IEEE International Conference on Image Processing, pages 461–464. IEEE, 2010. [5] Eugen Wige, Gilbert Yammine, Wolfgang Schnurrer, and Andre Kaup. ´ Mode adaptive reference frame denoising for high fidelity compression in hevc. In 2012 Visual Communications and Image Processing, pages 1–6. IEEE, 2012. [6] Antoni Buades, Bartomeu Coll, and J-M Morel. A non-local algorithm for image denoising. In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), volume 2, pages 60–65. IEEE, 2005. [7] Kostadin Dabov, Alessandro Foi, Vladimir Katkovnik, and Karen Egiazarian. Image denoising by sparse 3-d transform-domain collaborative filtering. IEEE Transactions on Image Processing, 16(8):2080– 2095, 2007. [8] Eugen Wige, Gilbert Yammine, Peter Amon, Andreas Hutter, and Andre Kaup. Efficient coding of video sequences by non-local in- ´ loop denoising of reference frames. In 2011 18th IEEE International Conference on Image Processing, pages 1209–1212. IEEE, 2011. [9] Kostadin Dabov, Alessandro Foi, and Karen Egiazarian. Video denoising by sparse 3d transform-domain collaborative filtering. In 2007 15th European Signal Processing Conference, pages 145–149. IEEE, 2007. [10] Matteo Maggioni, Giacomo Boracchi, Alessandro Foi, and Karen Egiazarian. Video denoising, deblocking, and enhancement through separable 4-d nonlocal spatiotemporal transforms. IEEE Transactions on image processing, 21(9):3952–3966, 2012. [11] The WebM Project. https://chromium-review.googlesource.com. [12] P. Wennersten. Encoder-only gop-based temporal filter. ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11, Document: JCTVC-AI0023- v2, 2019. [13] Joseph Salmon. On two parameters for denoising with non-local means. IEEE Signal Processing Letters, 17(3):269–272, 2009. [14] Cheng Chen, Jingning Han, and Yaowu Xu. Video denoising for the hierarchical coding structure in video coding. IEEE Sigport, 2020. [15] Alliance for Open Media. https://aomedia.googlesource.com/aom/. [16] Shen-Chuan Tai and Shih-Ming Yang. A fast method for image noise estimation using laplacian operator and adaptive edge detection. In 2008 3rd International Symposium on Communications, Control and Signal Processing, pages 1077–1081. IEEE, 2008.