VVC 中的残差编码,分为regular residual coding (RRC)和transform skip residual coding (TSRC)。 TSRC 和 RRC 都建立在 HEVC 中针对可变变换块大小 引入的 4 × 4 子块 (SB) 的概念之上,通常也称为系数组 (CG)。 图 1 说明了将大于 4 × 4 的块分解为 4 × 4 CG 以及 TSRC 的相关对角线扫描模式。 由于 TSRC 设计源自 RRC 设计,因此以下段落简要概述了 RRC 设计以及导致 TSRC 设计的修改。 请注意,由于变换块支持非正方形矩形,因此 VVC 支持非 4×4 子形状,这与仅支持 4×4 SB 的 HEVC 形成对比。 然而,在不失一般性的情况下,以下描述使用术语 CG 在解析过程的变换块内也包括非 4 × 4 子形状
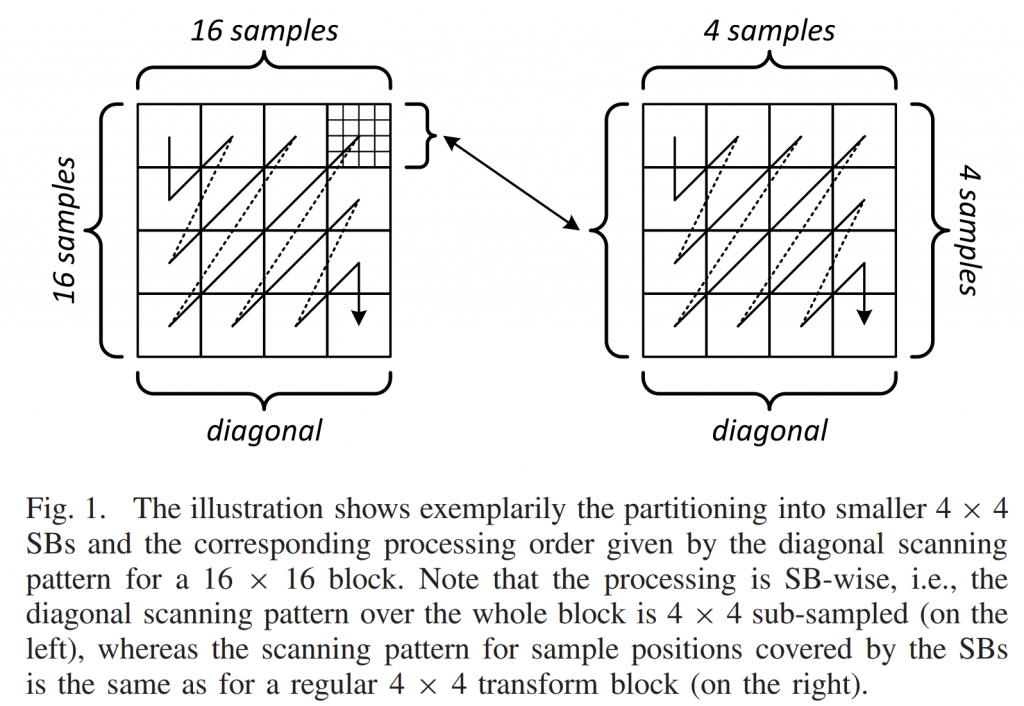
RRC 设计使用多级显著性指示,即嵌入到 4 × 4 CG 概念中的非零系数的存在,以便为变换和量化的残差信号提供有效的信号。 在处理变换块的变换系数之前,语法元素\( s_{cbf}\) 出现在比特流语法中,表示对整个变换块的显著性,\( s_{cbf}=0\) 暗示变换块内的所有变换系数都等于零。 当 \( s_{cbf}=1\)指示存在至少一个不等于零的变换系数时,则处理使用变量\( v^X_{last}\)和 \( v^Y_{last}\)继续最后有效扫描位置。 正如它们的名称所示,变量分别根据列和行位置指定变换块内最后一个变换系数的位置,当沿对角线扫描模式扫描时,每个相对于变换块的左上角,如下图 1所示。这意味着当沿着对角线扫描模式向块的末端扫描超过最后一个有效扫描位置时,块中没有进一步的有效变换系数。 请注意,两个变量 \( v^X_{last}\)和\( v^Y_{last}\)中的每一个的值都是从两个语法元素重建的,这两个语法元素指定了最后一个变换系数的列或行位置的前缀和(可能为空)后缀部分。
RRC中的变换系数解析过程从最后一个有效扫描位置开始,并使用反向对角线扫描模式来处理位于扫描路径上的所有频率位置朝向DC频率位置。 对于变换块的每个 4 × 4 CG,语法元素 \( s_{csb}\) 指示当前 CG 的显著性。 有两个例外,第一个是覆盖最后一个有效扫描位置的CG,第二个是覆盖 DC 频率位置的 CG,其中符合标准的解码器推断 \( s_{csb}\)。由于最后一个有效扫描位置已经在 CG,解码器可以为相应的 CG 推断 \( s_{csb}\)。 由于 CG 传输覆盖 DC 频率位置的显着水平的可能性很高,由于变换的能量压缩特性,符合标准的解码器总是推断左上角 CG 的\( s_{csb}\)。 然而,对于左上 CG的语法元素\( s_{sig}\)(指定扫描位置的显著性),与其他CG一样,没有推理规则,即,当在前15个扫描位置内没有出现显著水平时,由于 \( s_{csb}=1\),CG的最后一个扫描位置必须是显著的。在4×4变换块的情况下,CG满足上述两个特殊条件,解码器推断\( s_{csb}\)等于1。
1 Processing Order
RRC 和 TSRC 的一个主要区别是处理扫描模式的顺序相反,即使用常规的正向扫描顺序而不是 TSRC 沿对角线扫描模式的反向扫描顺序,如图 1 所示。 因为通常帧内预测对于远离所使用的参考样本(位于当前块的上方和左侧)的样本位置变得效率较低。 这也意味着空间域中的局部残差信号方差随着与参考样本的距离增加而变大,从而导致块右下角的电平值变大。 通过反转反向扫描顺序,即通过使用常规的前向对角线扫描顺序,当在频域中沿反向扫描顺序操作时,显著级别的概率在扫描顺序中增加,类似于 RRC 中的情况。 虽然帧间预测块的好处并不显着,但改变扫描模式方向不会对这种情况下的性能产生不利影响。 请注意,HEVC RExt 中使用的 180° 剩余旋转利用了相同的现象,但由于 SB-wise 处理,它实际上与改变扫描方向不同。
第二个主要区别是消除了 TSRC 中最后一个有效扫描位置的信号通知,导致处理块内的所有扫描位置,如图 1 所示。 然而,多级显著性指示在 \( s_{csb}\) 出现在变换块的所有 CG 的意义上仍然有效,其中变换块的最后一个(右下)CG构成一个例外。对于该特殊CG,一致解码器可以推断\( s_{csb}=1\) ,但仅当\( s_{csb}=0\) 用于所有先前处理的SB时。
2 Level Coding
正如在 RRC 设计中一样,TSRC 的量化索引(级别)的编码和解码在CG内的多个编码通道中进行,即,从解码器的角度来看,解析过程在每个通道上迭代多次,沿着 CG内的扫描模式扫描位置,直到解码器可以重建完整的级别信息。 对于 TSRC,量化索引在3个pass中编码(和解码),前提是不超过上下文编码 bin 的限制。
pass-1以交错方式为每个量化索引包含最多 4 个上下文编码语法元素: \( s_{sig}\)、 \( s_{sign}\)、 \( s_{gt1}\)和 \( s_{par}\),分别是显著性指示、符号、大于 1 标志以及奇偶校验标志。 值得注意的是,RRC 中的 \( s_{sig}\)编码使用了 CABAC 引擎的旁路模式,并作为最终通道出现,而 TSRC 中的 \( s_{sign}\) 编码是采用自适应上下文模型的pass-1编码的一部分。 虽然在 TSRC 中\( s_{sign}\) 的总体概率仍然大致等于 0.5,但对于空间域中变换跳过的残差信号,局部通常会偏向某个方向。 使用利用该统计异常的自适应上下文模型可以提高 TSRC 的编码效率。 请注意,pass-1还包括为网格编码量化 (TCQ)引入的 \( s_{par}\)语法元素(指定级别的奇偶性)。 尽管 TSRC 的 TCQ 不活跃,但 TSRC 的二值化过程保持\( s_{par}\),以便为两个残差编码路径的pass-1编码保持相似的语法元素列表。
TSRC 中的pass-2由最多 4 个额外的 bin 组成,这些 bin 是上下文编码的,指示每个绝对量化索引的greater-than-x (gtx) 属性相对于阈值 x ∈ {3, 5, 7, 9} 与 相关语法元素 sgt3、sgt5、sgt7 和 sgt9。
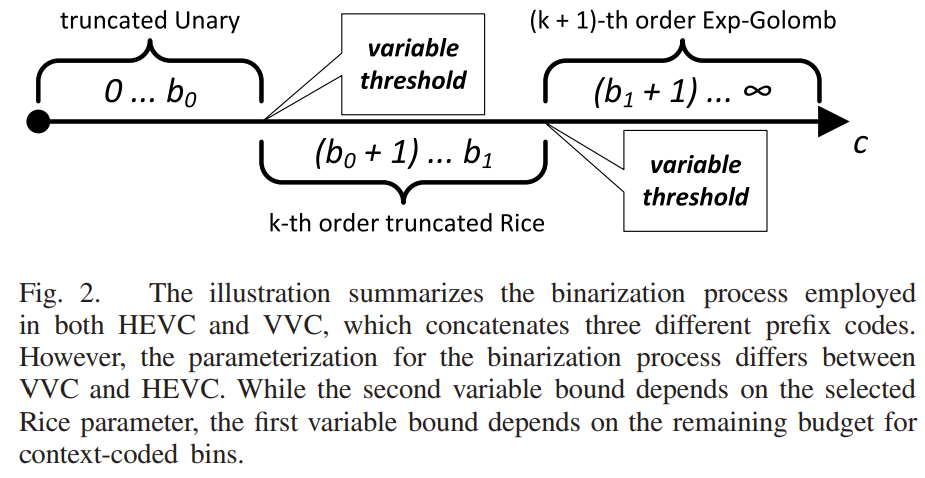
pass-3最终指定了在前面的编码过程中未完全传输的那些绝对量化索引的剩余部分,并且所有此类相关的 \( s_{rem}\) 语法元素都通过截断 Rice (TR) 和 Exp-Golomb (EG) bin 字符串的串联进行二值化,每个 bin 都像在 RRC 路径中一样进行旁路编码。
从概念上讲,二值化和绝对量化索引编码过程之间存在直接关系。 图 2 说明了 HEVC 和 VVC 中的二值化过程,包括 3 个具有不同参数化的不同前缀代码的串联。 原则上,与截断一元 (TU) bin 字符串相关的所有 bin 使用自适应上下文模型进行上下文编码,而与 TR 和 EG bin 字符串相关的 bin 使用 CABAC 引擎的旁路模式进行编码。 HEVC 和 VVC 二值化过程之间最显着的区别是 TCQ的奇偶\( s_{par}\)语法元素,对于 RRC,当启用 TCQ 时,奇偶标志驱动 TCQ 状态机,其在第一个编码通道中的信号避免了 在知道下一个扫描位置的 TCQ 状态之前,需要重建每个扫描位置的完整级别信息。 请注意,TCQ 状态是 RRC 中 \( s_{sign}\) bin 上下文建模的重要元素。 从二值化的角度来看,每对具有不同奇偶校验的两个连续绝对级别 {(2n, 2n + 1)|n ∈ N+} 共享相同的二进制码字表示。 因此,对于所有 c ≥ 2,必须对图 2 中表示绝对水平值的 c 轴进行二次采样,从而将二值化过程应用于绝对水平集 c ∈ {0, 1}∪{2n|n ∈ N+} 而不是 HEVC 的 c ∈ N0。 另一个结果是,只要 c ≥ 2,就需要通过在适当的 bin 索引处添加表示 \( s_{par}\) 的奇偶校验 bin 来完成生成的 bin 字符串。在 RRC 和 TSRC 中,关联的 TU bin 字符串的索引顺序是这样的奇偶校验 bin 始终放在表示 \( s_{gt1}\) 的大于 1 的 bin 之后。 请注意,对于 TSRC,必须在所有 c ≥ 1 的 \( s_{sign}\) bin 之后添加表示语法元素 \( s_{sign}\) 的另一个 bin,如上文已经讨论的那样。 对于余数编码通道,TSRC 对 TR 和 EG 二值化采用相同的第二阈值 b1 和固定 Rice 参数 k = 1。
3 Context Modeling
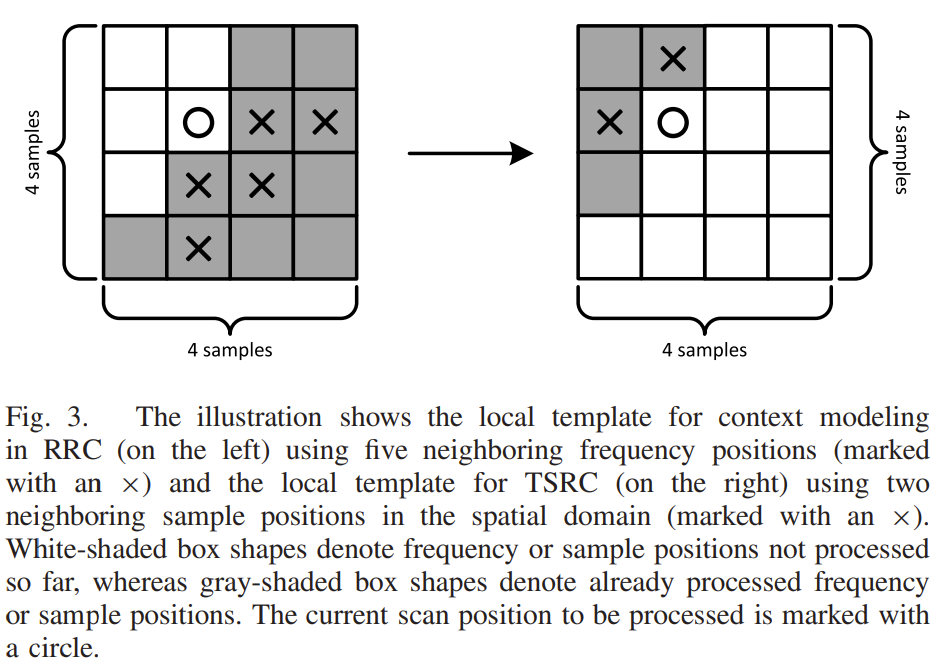
对于上下文建模,TSRC 采用类似于 RRC 路径但相邻位置较少的局部模板 T 进行评估。 图3左侧为RRC路径的本地模板和已经处理的相邻频率位置,右侧为TSRC对应的本地模板。 请注意,由于反向对角线扫描模式,局部模板在 RRC 中跨越到右侧和底部,而在 TSRC 中,局部模板是反转的,即它跨越到空间中当前扫描位置的左侧和顶部。 TSRC 中的上下文建模不是评估五个邻居,而是只评估当前扫描位置上方和左侧的空间邻居。
令 χ ∈ X 表示上下文模型集 X 内的上下文记忆偏移量,其中每个上下文模型集 X 具有固定偏移量,因此所有上下文模型集都是不相交的。 进一步,设 TA(s) 和 TL (s) 分别为上邻居和左邻居的评价结果。 然后,语法元素 \( s_{sign}\) 的上下文模型索引 χsig ∈ Xsig 与 |Xsig| = 3 等于
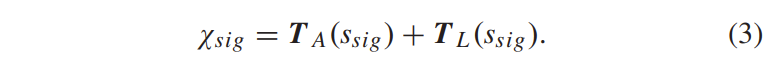
相同的规则适用于 \( s_{gt1}\),但触发单个专用上下文模型的 BDPCM 模式除外 (|Xgt1| = 4)
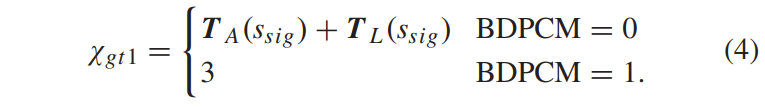
\( s_{sign}\) 语法元素的上下文建模比较本地模板覆盖的相邻样本值,并选择符号上下文模型集合 Xsign 的第一个上下文模型(χsign = 0)与 |Xsign| = 6 当两个邻居都不重要时 (TA(ssig ) = 0∧TL(ssig ) = 0) 或两个符号值不同 (TA(ssign) ≠TL(ssign))。 请注意,仅当两个相邻位置都包含显着水平时,第二个条件才成立。 当两个相邻位置中的一个由正水平组成时 (TA(ssign) = 1∨ TL(ssign) = 1),上下文建模选择集合的第二个上下文模型 (χsign = 1)。 所有其他情况都会导致使用第三个上下文模型 (χsign = 2)。 请注意,对于 BDPCM 模式,适用于 \( s_{sign}\) 语法元素的相同上下文建模,但固定偏移量等于 3,这意味着对于 BDPCM,使用一组单独的上下文模型。 属于第一个编码通道的 spar 语法元素和第二个编码通道的所有语法元素,即 sgt3、sgt5、sgt7 和 sgt9,使用单个专用上下文模型。
4 Limit on Context-Coded Bins
为了实现具有成本效益和可行的硬件实现,在 RRC 和 TSRC 的设计中纳入了变换块中每个系数的上下文编码箱 (ccb) 的最坏情况限制。 当 N 表示(变换)块中变换系数或样本的数量时,上下文编码箱的最大预算在级别编码开始时设置为 Bccb = 1.75× N。 对于每个上下文编码的编码通道和每个扫描位置,必须在实际执行编码通道之前检查条件 Bccb ≥ 4。 每当扫描位置发生 Bccb < 4 时,剩余电平信息的处理将回退到纯旁路编码模式,仅使用由 TR 和 EG bin 字符串组成的二值化,即图 2 所示的第一变量阈值 b0 是 设置等于 −1 的值.
5 Level Prediction
当当前扫描位置具有在pass-1通道中编码的电平信息时,处理在余数编码通道结束时应用电平预测技术。 从解码器的角度来看,上述和左邻域的绝对水平 (TA(c) 和 TL (c)) 用作预测变量 p = max{T A(c), T L(c)},并且以下三种情况之一适用。 如果当前绝对水平 c 等于 1 且预测变量大于 0 (c = 1 ∧ p > 0),则最终绝对水平等于预测变量值 (c = p)。 最终绝对水平小于或等于预测变量值时减一,否则不变,总结如下:
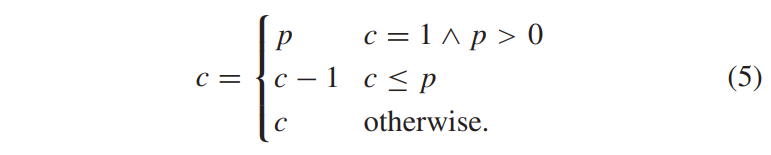
请注意,级别预测技术等效于二值化过程的修改,即级别预测将 bin 字符串交换为 c = 1 和 c = p。 此外,当 BDPCM 对当前块有效时,不应用电平预测。