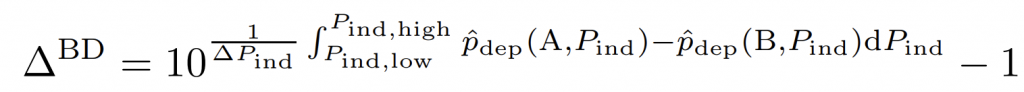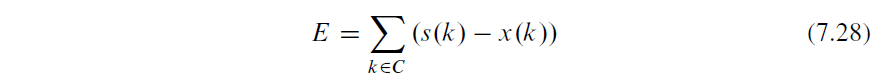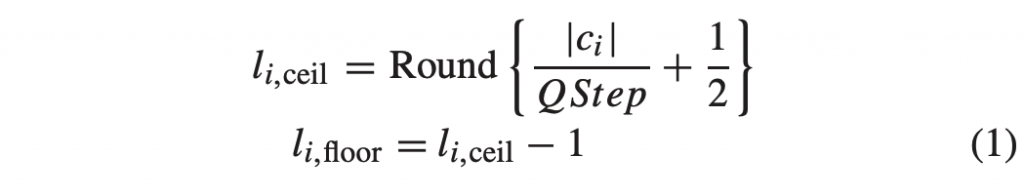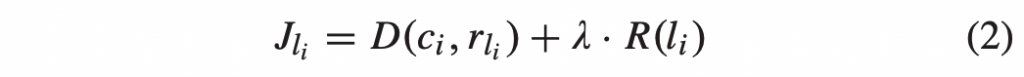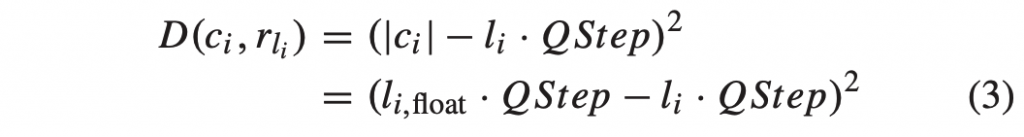PGO(Profile-guided optimization)通常也叫做 FDO(Feedback-directed optimization),它是一种编译优化技术,它的原理是编译器使用程序的运行时 profiling 信息,生成更高质量的代码,从而提高程序的性能。
传统的编译器优化通常借助于程序的静态分析结果以及启发式规则实现,而在被提供了运行时的 profiling 信息后,编译器可以对应用进行更好的优化。通常来说编译反馈优化能获得 10%-15% 的性能收益,对于特定特征的应用(例如使用编译反馈优化 Clang本身)收益高达 30%。
编译反馈优化通常包括以下手段:
- Inlining,例如函数 A 频繁调用函数 B,B 函数相对小,则编译器会根据计算得出的 threshold 和 cost 选择是否将函数 B inline 到函数 A 中。
- ICP(Indirect call promotion),如果间接调用(Call Register)非常频繁地调用同一个被调用函数,则编译器会插入针对目标地址的比较和跳转指令。使得该被调用函数后续有了 inlining 和更多被优化机会,同时增加了 icache 的命中率,减少了分支预测的失败率。
- Register allocation,编译器能使用运行时数据做更好的寄存器分配。
- Basic block optimization,编译器能根据基本块的执行次数进行优化,将频繁执行的基本块放置在接近的位置,从而优化 data locality,减少访存开销。
- Size/speed optimization,编译器根据函数的运行时信息,对频繁执行的函数选择性能高于代码密度的优化策略。
- Function layout,类似于 Basic block optimization,编译器根据 Caller/Callee 的信息,将更容易在一条执行路径上的函数放在相同的段中。
- Condition branch optimization,编译器根据跳转信息,将更容易执行的分支放在比较指令之后,增加icache 命中率。
- Memory intrinsics,编译器根据 intrinsics 的调用频率选择是否将其展开,也能根据 intrinsics 接收的参数优化 memcpy 等 intrinsics 的实现。
编译器需要 profiling 信息对应用进行优化,profile 的获取通常有两种方式:
- Instrumentation-based(基于插桩)
- Sample-based(基于采样)
Instrumentation
Instrumentation-based PGO 的流程分为三步骤:
- 编译器对程序源码插桩编译,生成插桩后的程序(instrumented program)。
- 运行插桩后的程序,生成 profile 文件。
- 编译器使用 profile 文件,再次对源码进行编译。

Instrumentation-based PGO 对代码插桩包括:
1. 插入计数器(counter)
- 对编译器 IR 计算 MST,计算频繁跳转的边,对不在 MST 上的边插入计数器,用于减少插桩代码对运行时性能的影响。
- 在函数入口插入计数器。
2. 插入探针(probes)
- 收集间接函数调用地址(indirect call addresses)。
- 收集部分函数的参数值。
Sampling
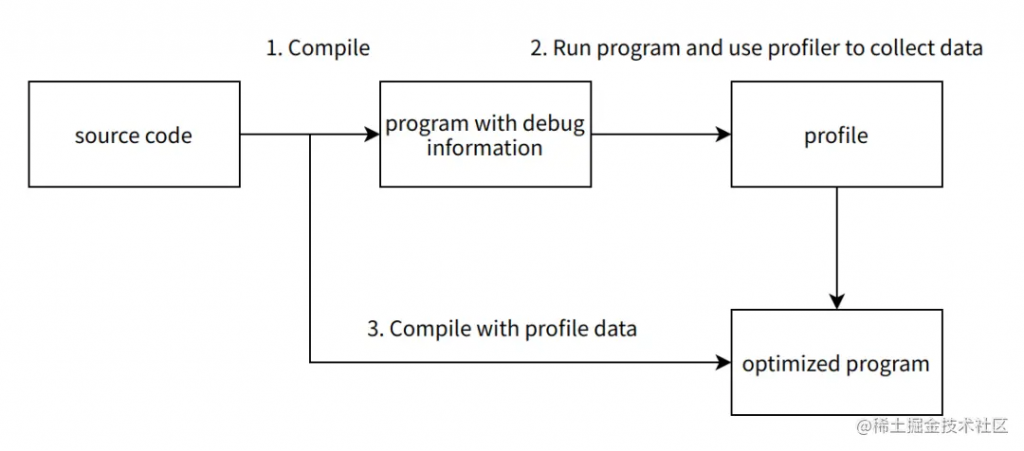
Sample-based PGO 的流程同样分为三步骤:
- 编译器对程序源码进行编译,生成带调试信息的程序(program with debug information)。
- 运行带调试信息的程序,使用 profiler(例如linux perf)采集运行时的性能数据。
- 编译器使用 profile 文件,再次对源码进行编译。
其中步骤2采集的数据为二进制级别采样数据(例如 linux perf 使用 perf record 命令收集得到 perf.data 文件)。二进制采样数据通常包含的是程序的 PC 值,我们需要使用工具,读取被采样程序的调试信息(例如使用 AutoFDO 等工具),将程序的原始二进制采样数据生成程序源码行号对应的采样数据,提供给编译器使用。
比较
对比 sampled-based PGO,Instrumentation-based PGO 的优点采集的性能数据较为准确,但繁琐的流程使其在业务上难以大规模落地,主要原因有以下几点:
- 应用二进制编译时间长,引入的额外编译流程影响了开发、版本发布的效率。
- 产品迭代速度快,代码更新频繁,热点信息与应用瓶颈变化快。而 instrumented-based PGO 无法使用旧版本收集的 profile 数据编译新版本,需要频繁地使用插桩后的最新版本收集性能数据。
- 插桩引入了额外的性能开销,这些性能开销会影响业务应用的性能特征,收集的 profile 不能准确地表示正常版本的性能特征,从而降低优化的效果,使得 instrumented-based PGO 的优点不再明显。
使用 Sample-based PGO 方案可以有效地解决以上问题:
- 无需引入额外的编译流程,为程序添加额外的调试信息不会明显地降低编译效率。
- Sample-based PGO 对过时的 profile 有一定的容忍性,不会对优化效果产生较大影响。
- 采样引入的额外性能开销很小,可以忽略不计,不会对业务应用的性能特征造成影响。