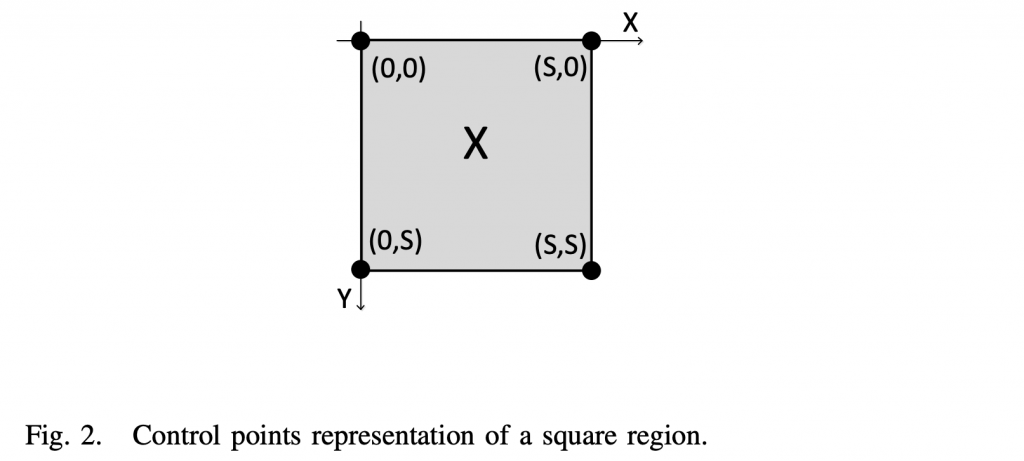
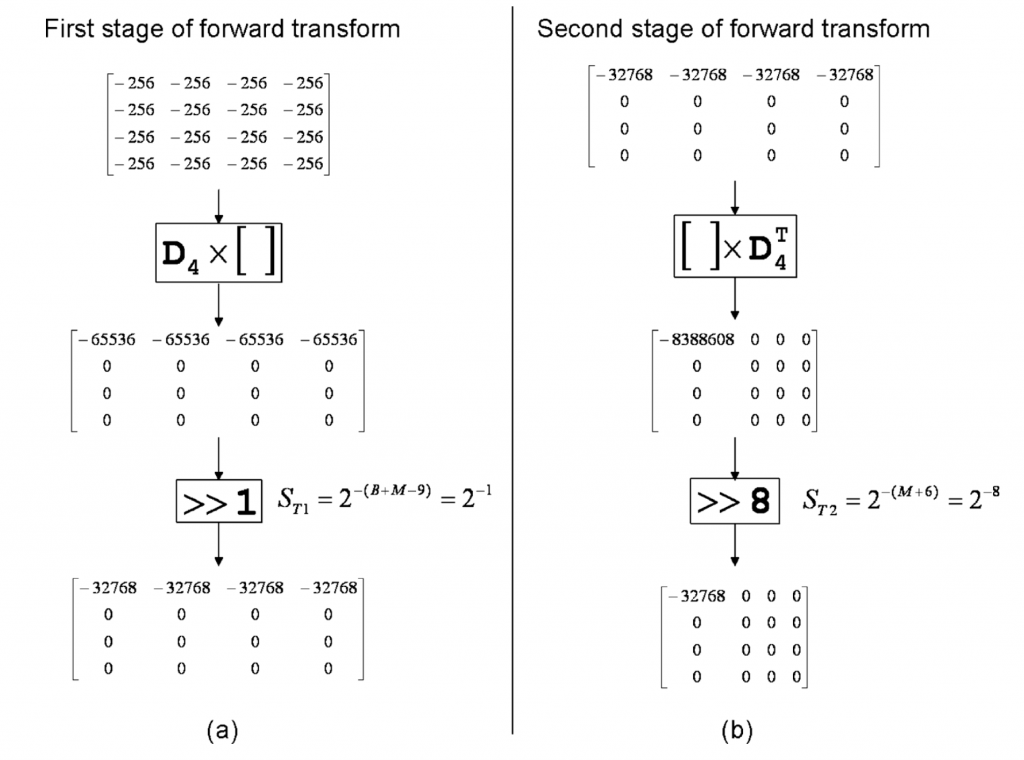
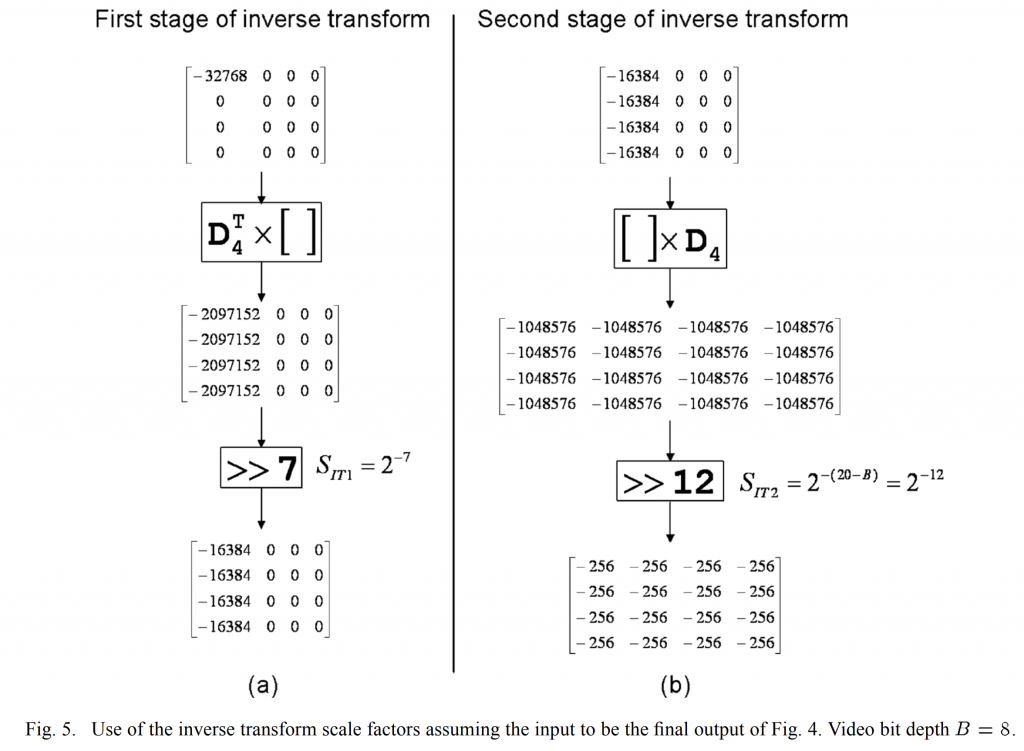
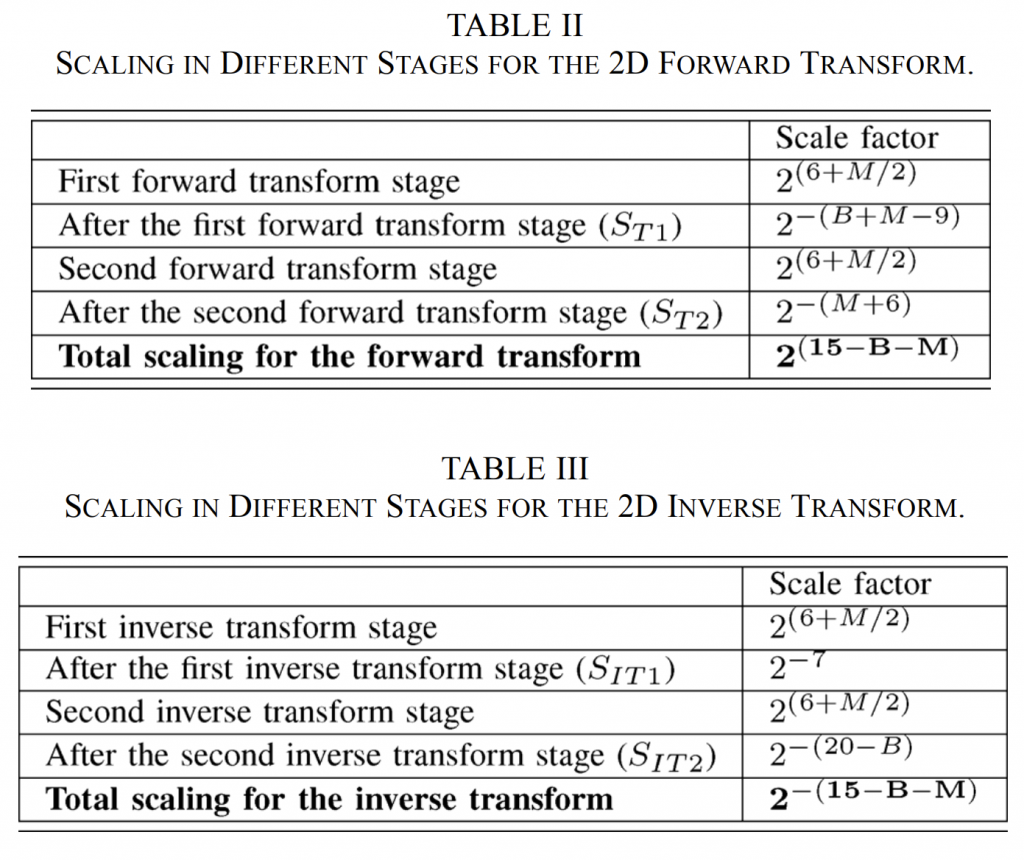
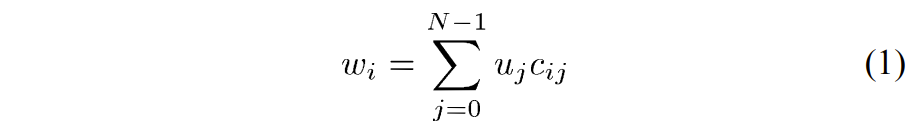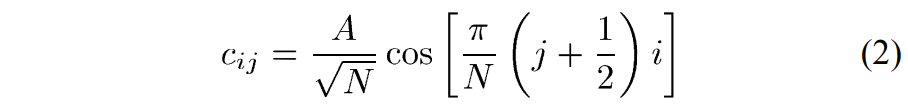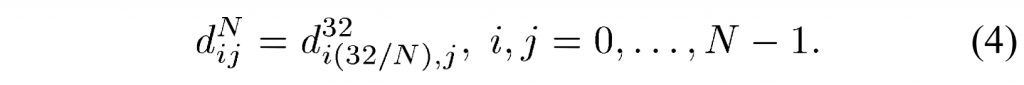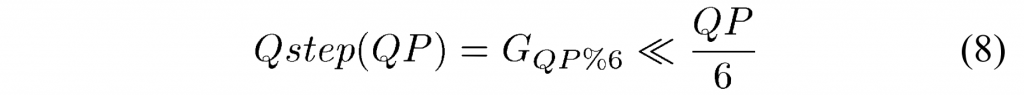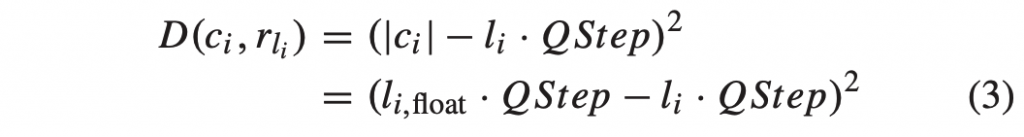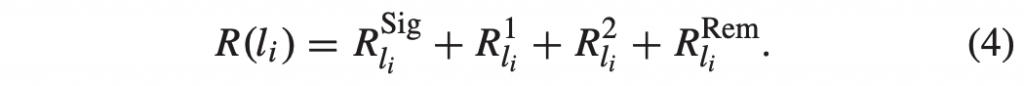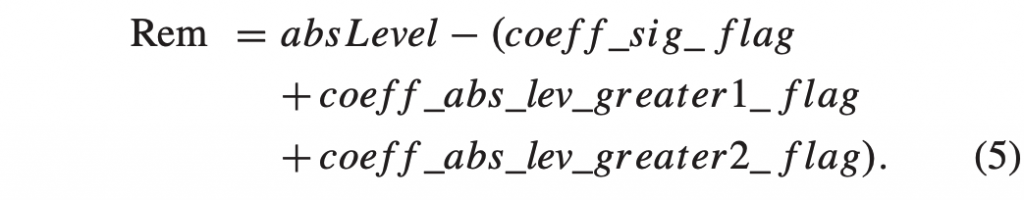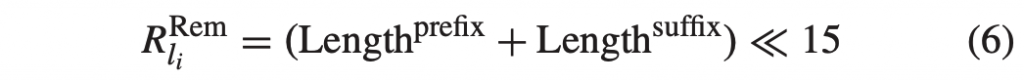1 POC and DPB
HEVC 中的每个图片都分配有一个图片顺序计数 (picture order count, POC) 值,表示为 PicOrderCntVal。 它具有三个主要用途:唯一地标识图片,指示相对于同一 CVS 中其他图片的输出位置,以及在较低级别的 VCL 解码过程中执行运动矢量缩放。 同一CVS中的所有图片必须具有唯一的POC值。 来自不同CVS的图片可以共享相同的POC值,但是图片仍然可以被唯一地识别,因为不可能将来自一个CVS的图片与另一CVS的任何图片混合。 CVS 中允许 POC 值存在间隙,即,输出顺序连续的两个图片之间的 POC 值差异可以相差超过1(事实上,连续图片的 POC 值的差异量可以任意变化) 。
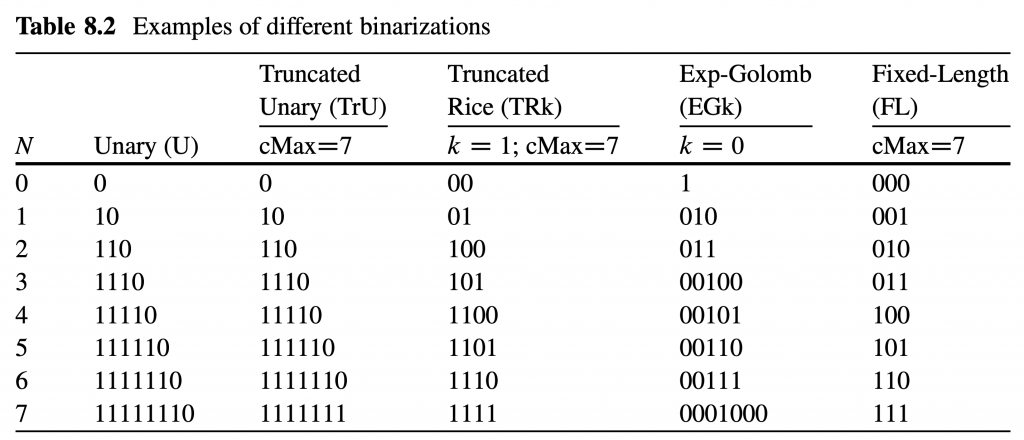
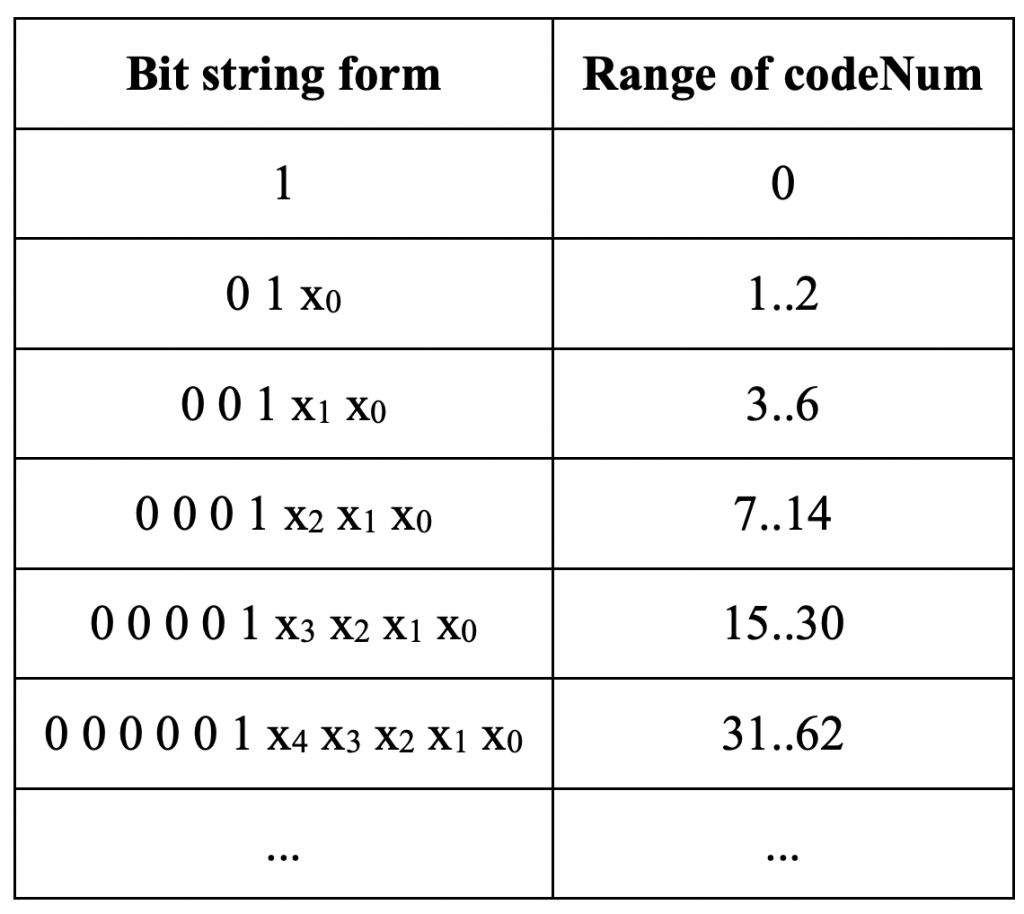
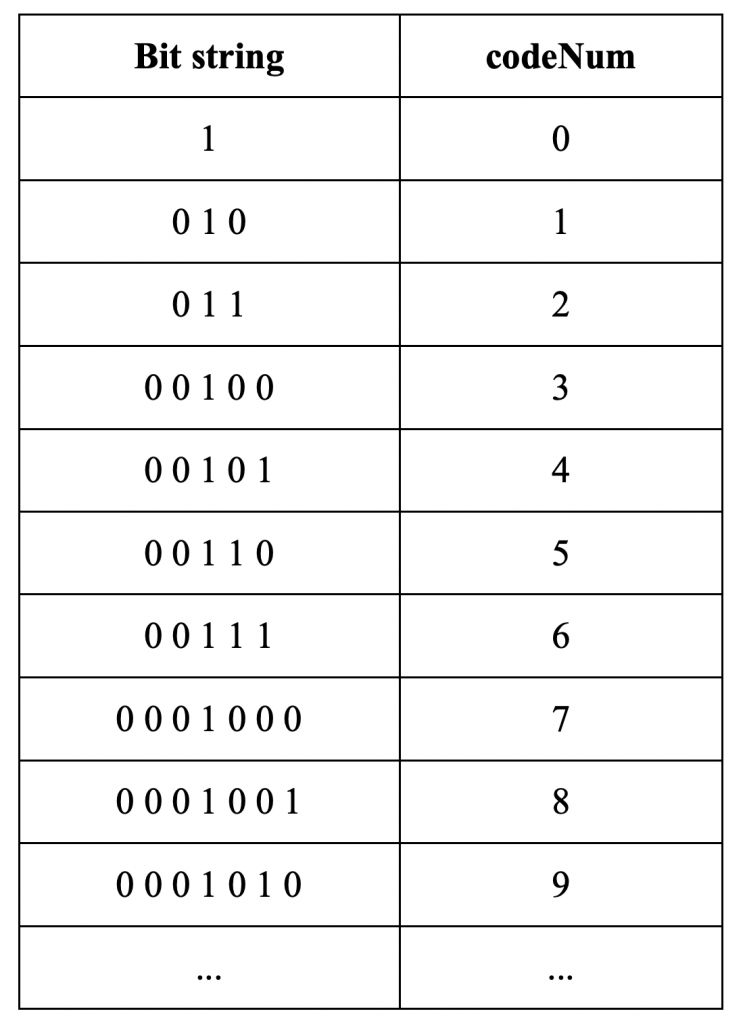
图片的 POC 值由slice header 中的 slice_pic_order_cnt_lsb 码字表示。 允许的 POC 值的范围是从 -231 到 231 – 1,因此为了节省 slice header 中的比特,仅用信号通知 POC 值的最低有效位 (POC LSB)。 用于 POC LSB 的位数可以在 4 到 16 之间,并在 SPS 中用信号通知。 由于在 slice header 中仅用信号通知 POC LSB,因此当前图片的最高有效 POC 值位 (POC MSB) 是从称为 prevTid0Pic 的先前图片导出的。 为了即使图片被移除,POC 推导也能以相同的方式工作,prevTid0Pic 被设置为时间层 0 的最近的先前图片,该图片不是 RASL 图片、RADL 图片或子层非参考图片。 解码器通过将当前图片的POC值与前一个图片的POC值进行比较来导出POC MSB值。
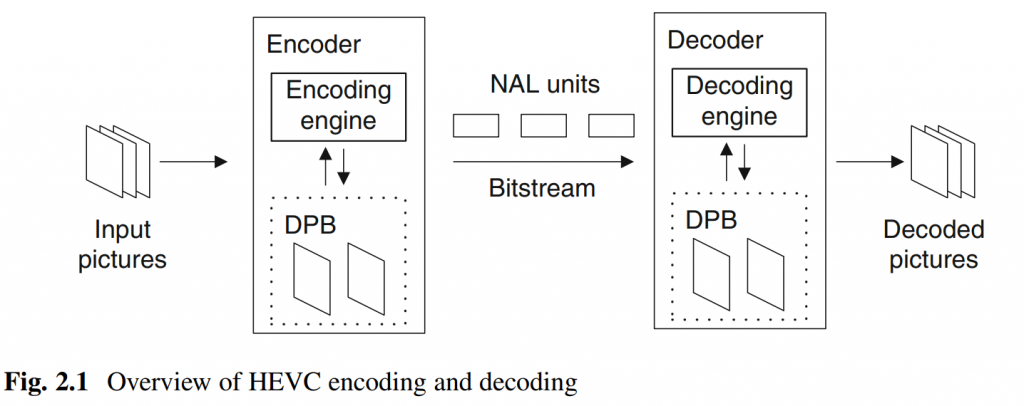
HEVC中的解码图片缓冲器(DPB)是包含解码图片的缓冲器。 除当前图片之外的解码图片可以存储在DPB中,因为它们需要参考,或者因为它们尚未输出,这是启用乱序输出所必需的。 请注意,当前解码的图片也存储在 DPB 中。 图 2.12 显示了两个示例引用结构,它们都需要至少三张图片的 DPB 大小。 图2.12a中的图片P1和P2都在P3之后输出,因此在P3解码时都需要将其存储在DPB中。 因此,DPB 需要能够同时存储 P1、P2 和 P3。 在图2.12b中,每个图片使用两个参考图片,因此DPB也需要足够大以同时存储三个图片。 图2.12b中的参考结构是所谓的低延迟B结构的示例,其中广泛使用双向预测而没有任何乱序输出。

解码器需要分配用于解码特定比特流的最小DPB大小由sps_max_dec_pic_buffering_minus1 码字来发信号通知,其可以针对序列参数集中的每个时间子层发送。 HEVC的第一版本中允许的最大可能的DPB大小是16,但是根据图片大小和所使用的解码能力的“级别”的组合,最大大小可以进一步受到限制。 请注意,HEVC 指定要包括在 DPB 中的当前图片,因此 DPB 大小为 1 将不允许任何参考图片。 如果DPB大小为1,则所有图片都必须进行帧内编码。
DPB中的图片被标记以指示它们的参考状态。 DPB中的每张图片都被标记为“不用于参考”、“用于短期参考”或“用于长期参考”。 通常将这些类型的图片分别称为非参考图片、短期图片和长期图片。
参考图片要么是短期图片,要么是长期图片。不同之处在于,长期图片可以在DPB中保存的时间比短期图片长得多。有一条规则决定了短期图片可以在DPB中停留多长时间。由当前图片、prevTid0Pic、DPB中的短期参考图片和DPB内等待输出的图片组成的图片集的POC跨度必须在POC LSB覆盖的POC范围的一半以内。该规则保证了POC MSB推导的正确性,并通过使解码器能够识别丢失的短期图片来提高误差鲁棒性。
非参考图片是不用作参考但如果以后需要输出时仍可以保留在DPB中的图片。
如图 2.13 所示,每个解码图像的图像标记都会发生变化。 图片被解码后,最初总是被标记为短期图片。 短期图片可以保持短期图片或改变为非参考图片或长期图片。 长期图片可能会保持长期图片或变成非参考图片,但它们永远不能再变成短期图片。 非参考图片永远不能再次成为参考图片。

DPB中的图片可以被保存以供将来输出,无论它是参考图片还是非参考图片。 当图片已被解码时,它通常等待输出,除非 slice header 中的pic_output_flag等于0或者图片是与CVS中的第一图片相关联的RASL图片。 如果是这种情况,则不会输出图片。
图片标记和图片输出是在单独的过程中完成的,但是当图片既是非参考图片并且不等待输出时,DPB中的图片存储缓冲器被清空并且可以用于存储将来的解码图片。 编码器负责管理图片标记和图片输出,以便 DPB 中的图片数量不超过 sps_max_dec_pic_buffering_minus1 指示的 DPB 大小。
SPS中与图片输出相关的另外两个码字是
sps_max_num_reorder_pics 和 sps_max_latency_increase_plus1,两者都可以针对每个时间子层发送。 sps_max_num_reorder_pics,此处表示为NumReorderPics,指示在解码顺序中可以在任何图片之前并且在输出顺序中在其之后的图片的最大数量。 图 2.12a 中的参考结构的 NumReorderPics 值为 2,因为图片 P3 有两个图片在解码顺序上位于其前面,但在输出顺序上位于其后面。 图 2.12b 的 NumReorderPics 为零,因为没有图片乱序发送。
sps_max_latency_increase_plus1 用于指示 MaxLatencyPictures,它指示在输出顺序中可以在任何图片之前并且在解码顺序中在该图片之后的图片的最大数量。 图 2.14 显示了 NumReorderPics 和 MaxLatencyPictures 之间的区别。 NumReorderPics 在此等于 1,因为 P1 是唯一乱序发送的图片。 MaxLatencyPictures 设置为 4,因为图片 P2、P3、P4 和 P5 在输出顺序上都先于 P1。 此参考结构的最小 DPB 大小为 3。

可以说NumReorderPics表示DPB中处理乱序图片所需的图片存储的最小数量,而MaxLatencyPictures表示由乱序图片引起的以图片为单位的最小编码延迟量。
对于低延迟应用,建议使用不会因乱序输出而导致编码延迟的参考结构。 这是通过确保解码顺序和输出顺序相同来实现的,这可以通过发信号通知 NumReorderPics 或 MaxLatencyPictures 或两者都等于 0 来表示。
2 Reference Picture Sets
将图片标记为“用于短期参考”、“用于长期参考”或“不用于参考”的过程是使用参考图片集(RPS)概念来完成的。 RPS是在每个slice header中用信号通知的一组图片指示符,并且由一组短期图片和一组长期图片组成。 在图片的第一个片头被解码之后,DPB中的图片被标记为由RPS指定的。
RPS的短期图片部分中指示的DPB中的图片被保留为短期图片。 将RPS中的长期图像部分中指示的DPB中的短期或长期图像转换为或保留为长期图像。 最后,DPB中RPS中没有指示符的图片被标记为未使用以供参考。 因此,可以用作对按照解码顺序的任何后续图片进行预测的参考的所有已经解码的图片必须被包括在RPS中。
RPS 由一组图片顺序计数 (POC) 值组成,用于识别 DPB 中的图片。 除了用信号发送 POC 信息之外,RPS 还为每张图片发送一个标志。 每个标志指示对应的图片是否可供当前图片参考。 注意,即使参考图片被信号通知为对于当前图片不可用,它仍然被保存在DPB中并且可以供稍后参考并用于解码未来的图片。 根据 POC 信息和可用性标志,可以创建如表 2.3 所示的五个参考图片列表。

列表RefPicSetStCurrBefore由可用于当前图片的参考并且具有低于当前图片的POC值的POC值的短期图片组成。 RefPicSetStCurrAfter 由可用的短期图片组成,其 POC 值高于当前图片的 POC 值。 RefPicSetStFoll是包含对于当前图片不可用但可以用作用于按解码顺序解码后续图片的参考图片的所有短期图片的列表。 最后,列表RefPicSetLtCurr和RefPicSetLtFoll分别包含可用于和不可用于当前图片的参考的长期图片。
图 2.15 和表 2.4 显示了使用三个时间子层的示例引用结构以及按解码顺序排列的每个图片的 RPS 列表的内容。
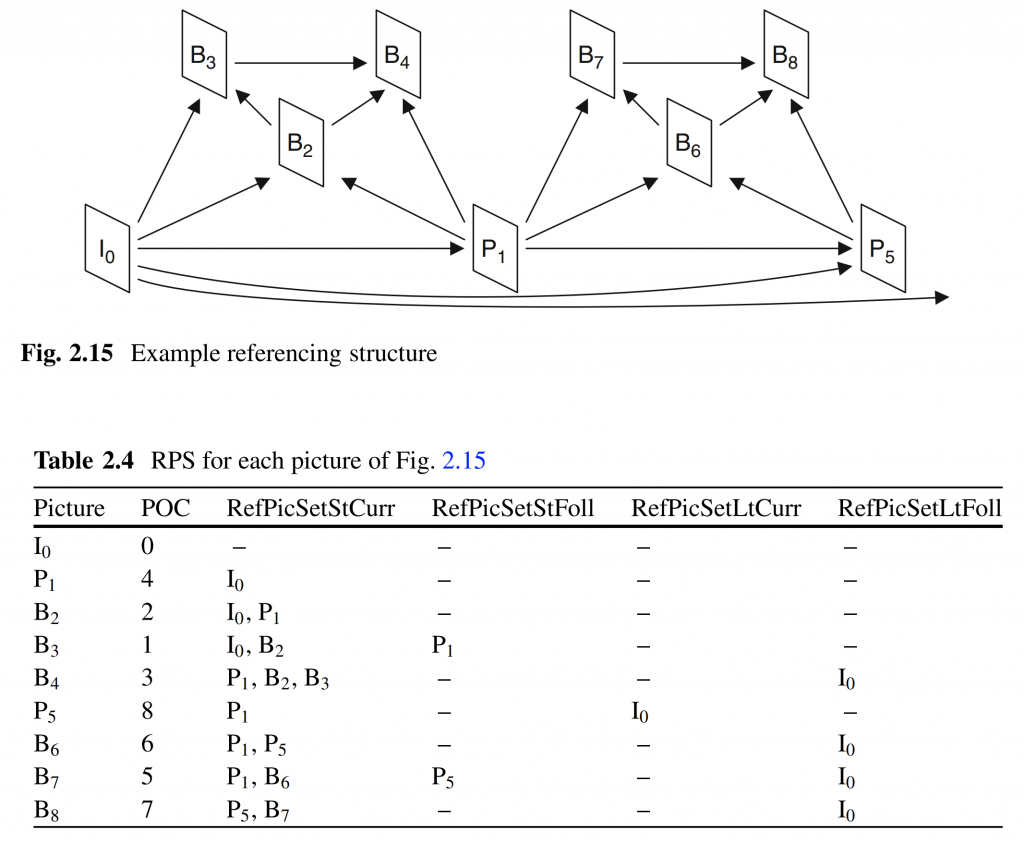
IDR图片重置编解码器,包括将DPB中的所有图片转变为非参考图片。 由于IDR图片的RPS是空的,因此没有为IDR图片用信号发送RPS语法。 因此表 2.4 中的所有列表对于 IDR 图片 I0 都是空的。 在图片B3处,图片P1被放入RefPicSetStFoll中,因为P1未被B3引用。 然而,P1 保留在 DPB 中,因为它用于将来的图片。 在图片B4处,本例中I0被制作为长期图片,因此由于B4没有引用它,因此将其放入RefPicSetLtFoll中。 在图片P5处,编码器通过根本不将图片B2和B3包括在RPS中来使图片B2和B3成为非参考图片。 同时,图片 I0 被移动到 RefPicSetLtCurr,因为它被 P5 引用。 此后,I0 保存在 RefPicSetLtFoll 中以供以后使用。
编码器需要确保RefPicSetStCurr和RefPicSettRoll中指示的每个图片都存在于DPB中。如果不是这种情况,解码器应该将其推断为比特流错误,并采取适当的行动。然而,如果在RPS中的条目的DPB中不存在被指示不用于当前图片的参考的对应图片,则解码器不采取任何动作,因为这种情况可能由于移除个别子层非参考图片或整个较高时间子层而发生。
尽管没有针对IDR图片发送RPS,但是CRA和BLA图片都可以在其RPS中具有图片,使得相关联的RASL图片可以使用RPS中的那些图片作为预测的参考。但是,对于CRA和BLA图片,要求RefPicSettCurr和RefPicSetLtCurr列表均为空。
3 Reference Picture Set Signaling
对于RPS中的每个图片,用信号发送三条信息:POC信息、可用性状态以及图片是短期图片还是长期图片。
短期图片的 POC 信息以两组方式发送。 组 S0 首先被发信号通知,它由 POC 值低于当前图片的所有短期图片组成。 该组之后是组 S1,其包含具有比当前图片更高的 POC 值的所有短期图片。 每组的信息按照相对于当前图片的POC距离顺序发送,从最接近当前图片的POC值的POC值开始。 对于每张图片,都会发出相对于前一张图片的 POC 增量信号。 当前图片充当每组中第一张图片的前一张图片,因为第一张图片没有前一张图片。
通过 POC 增量对长期图片进行编码可能会导致非常长的码字,因为长期图片可以在 DPB 中保留很长时间。 因此,长期图像而是通过其 POC LSB 值来表示。 用于slice header POC LSB 值的相同位数也用于长期图片。 解码器会将 RPS 中发信号通知的每个 POC LSB 值与 DPB 中图片的 POC LSB 值进行匹配。 由于 DPB 中可能有多个具有相同 POC LSB 值的图片,因此还可以选择发送长期图片的 POC MSB 信息。 当存在解码器无法正确识别图片的风险时,必须发送此 MSB 信息。 避免这种风险的一种方法是,当相应的 POC LSB 值已被两个或多个不同的长期图片使用时,始终用信号发送长期图片的 POC MSB 信息。
RPS 中每个图片的可用性状态由一位标志表示,其中“1”表示该图片可供当前图片参考,“0”表示不可用。
表 2.5 显示了图 2.15 中图片 B7 的示例 RPS 语法。 表中的第一列显示语法是否与发信号通知短期图片或长期图片相关。 第二列包含每个语法元素的 HEVC 规范名称。 第三列表示RPS中的相关图片,第四列表示示例中语法元素的值。 第五列显示语法元素的类型,其中“uvlc”表示通用可变长度代码,“flag”是一位二进制标志,“flc”是固定长度代码。 最后一列显示使用类型对每个语法元素的值进行编码的结果位。

图2.15中图片B7的POC值为5,其RPS包含3个短期图片; S0组中的图片P1和S1组中的图片B6和P5。 RPS 的前两个语法元素传达 S0 和 S1 中的图片数量; 这是由 uvlc 代码“010”和“011”编码的。 然后用信号发送组S0中的图像。 P1 的 POC 增量为 1,因为它的 POC 值为 4,并且当前图片的 POC 值等于 5。在编码之前,POC 增量减去 1,因此最终信号值为 0,这导致 uvlc 代码“1” 。 当前图片B7以图片P1为参考; 这是由标志“1”表示的。
接下来的语法元素涵盖了 S1 中的图片。 当前图片的 POC 值等于 5,因此代码字“1”用于 B6,因为其 POC 值等于 6。图片 B6 也用于由标志“1”指示的当前图片的参考。 S1 中的第二张图片是 P5,其 POC 值为 8。它是相对于 S1 中的前一张图片(B6,POC 值为 6)进行编码的。增量为 2,减 1 等于 1,编码为 ‘010’。 当前图片B7不参考图片P5; 这是由标志“0”表示的。
RPS 中的下一个码字表示 RPS 中长期图像的数量,它是 1,并且使用“010”进行 uvlc 编码。 然后用信号通知长期图像I0的POC LSB值。 这是通过代码字“00000000”假设 8 位用于发送 POC LSB 值。 长期图片I0不被当前图片B7参考; 这是用标志‘0’来表示的。 最后,由于 DPB 中没有其他图片共享相同的 POC LSB 值,因此不会针对该长期图片发送 POC MSB 信息; 这是用当前标志“0”来表示的。
出于弹性原因,RPS信息在每个 slice header 中用信号发送,但是对于每个 slice 按原样重复RPS信息可能会花费许多比特。不仅可以将图片分割成必须重复RPS的多个slice,比特流中的图片通常通过重复相同的GOP结构来编码,因此对于在GOP结构中共享相同位置的图片重复相同的RPS信息。
为了利用冗余并降低总体比特成本,可以在 SPS 中发送一些 RPS 语法在 slice header 中引用。 RPS的短期图像部分是相对于当前图像的POC值进行编码的。 这使得可以将多个短期RPS部分存储在SPS中的列表中,并且仅在 slice header 中用信号发送列表索引。 该列表可以包含用于GOP结构中的每个画面位置的一个RPS。 然后,SPS 中的 RPS 数量将等于 GOP 长度,并且每个片将仅需要发送列表索引以便用信号通知其短期图像部分。
发送每个GOP位置的RPS信息可能需要SPS中相对较多的比特,比如对于一些GOP结构存在数百比特。 为了节省 SPS 中的比特,HEVC 中可以选择使用 RPS 预测。 这要求以 GOP 解码顺序发送 RPS,并利用每个 RPS 与前一个类似的事实。 可以按照解码顺序将图片参考从一个RPS移除到下一个RPS,但是相对于前一RPS最多只能添加一张新图片。 HEVC 中的 RPS 预测机制正在利用此属性,相对于显式信令,可以实现 SPS 中 RPS 比特数最多减少 50%。
4 Reference Picture Lists
当P或B slice的 slice header 已被解码时,解码器为当前slice设置参考图片列表。 有两个参考图片列表,L0和L1。 L0 用于 P 和 B slice,而 L1 仅用于 B slice。 图2.16示出了使用五个参考图片进行预测的图片B7的参考图片列表示例。

首先,构建 L0 和 L1 的临时列表。 临时列表L0以RPS列表RefPicSetStCurrBefore中的图片开始,按POC值降序排序。 这些都是可供当前图片参考并且具有小于当前图片的POC值的POC值的短期图片。 因此图2.16中图片B7的临时列表L0以P1开始,随后是B2。 接下来是按 POC 值升序排序的 RPS 列表 RefPicSetStCurrAfter 中的图片,即图 2.16 中的 B6 和 P5。 最后添加可用的长期图片,因此图片I0是最后添加的图片。 图片B7的最终临时列表L0则为{P1、B2、B6、P5、I0}。 临时列表L1的设置与L0类似,但是RefPicSetStCurrBefore和RefPicSetStCurrAfter的顺序交换。 因此,图片B7的临时列表L1变为{B6、P5、P1、B2、I0}。
临时列表用于构建最终的L0和L1列表。L0和L1的长度在PPS中用信号发送,但可以被slice header 中的可选码字覆盖。列表的最大长度为15。如果L0或L1的指定长度分别小于临时列表L0或L2的长度,则通过截断相应的临时列表来构建最终列表。如果指定的长度大于相应临时列表的长度,则从临时列表中重复图片。例如,如果长度为2,L0等于{P1、B2},如果长度是9,则等于{P1,B2、B6、P5、I0、P1、B2、B6、P5}。启用比临时列表长的列表的原因是加权预测,以使不同的加权因子能够应用于相同的参考图片。
从临时列表构建 L0 和 L1 的另一种方法是通过显式列表信令。 在这种情况下,列表中的每个条目都有一个代码字,用于指定要使用临时列表中的哪个图片。 因此,如果指定L0的长度等于3,则有3个码字用于指定L0。 例如,如果这三个码字等于1、1、0,则当P1是临时列表L0中的第一图片且B2是第二图片时,列表L0变为{B2、B2、P1}。
最终列表L0和L1用于运动补偿。 对于单预测,为块指示一个运动向量和一个参考图片索引。 例如,如果块的信号索引等于 0,则 L0 中的第一张图片是用于运动补偿的图片。