这篇文章对于学习MCTF(运动补偿时域滤波 motion compensated temporal filtering)有很好的帮助。

摘要:
现代视频编解码器利用视频信号的时间和空间相关性来实现压缩。视频信号中的噪声破坏了这种相关性并损害了编码效率。先前在VP8、VP9和HEVC中的工作利用了时间滤波来去除源信号中的某些噪声。它们通常比较沿运动轨迹的一对像素,并基于像素值差确定滤波器系数。观察到,这种噪声去除允许更好的速率失真性能折衷。请注意,在所有情况下都针对原始视频信号评估压缩失真。本文提出了一种用于噪声去除的非局部平均时间滤波器。它不是比较运动轨迹上的一对像素,而是比较感兴趣像素周围的两个像素块。然后,它们在L2范数中的距离被帧噪声水平归一化,该噪声水平用于确定非参数模型中的时间滤波器系数。实验表明,与其他竞争者相比,所提出的非局部均值滤波方法获得了更好的压缩效率。
I. INTRODUCTION
视频编解码器利用视频信号的空间和时间相关性来实现压缩效率。源信号中的噪声因素减弱了这种相关性,阻碍了编解码器的性能。视频信号去噪是一种很有前景的解决方案。
采用各种去噪方法去除重构帧中的量化噪声在视频压缩研究中有着悠久的历史。Dubois和Sabri[1]指出,噪声和信号之间的主要区别在于噪声是不相关的,而视频信号具有很强的时间相关性。Boyce[2]建议使用自适应运动补偿帧平均方法来减少噪声。该算法是逐块的,并且在无位移帧平均和运动补偿帧平均之间切换。这些方法成功地降低了噪声并提高了视频帧的视觉质量。在VP8中,提出了一种内环去噪算法,以生成非显示帧,该帧被编码并存储在帧缓冲器中,用作其他显示帧的参考帧[3]。后来,针对H.264/AVC[4]和HEVC[5]提出了类似的想法。不同的滤波算法,如自适应维纳滤波器、非局部均值[6]、块匹配和三维滤波(BM3D)[7]在环路去噪框架[8]中进行了评估。其他作品[9]、[10]通过在高维空间中进行分组和协作过滤,利用自然视频序列中的时间和空间冗余,提高了视觉质量。
在各种编码器实现中,包括libvpx VP8、VP9[11]和HEVC[12],早就发现了从源视频信号中去除噪声作为目标压缩效率的预处理阶段的好处。它们通常使用常规块匹配运动搜索构建运动轨迹,并比较轨迹上的每对像素,其差值将用于确定时间滤波器系数。滤波后的帧被馈送到视频编解码器中,并将其重建与原始(无滤波)帧进行比较以计算失真。实验表明,它可以获得显著的压缩性能增益。
本文提出了一种用于源信号时域滤波的非局部均值滤波核。它不是比较一对像素之间的差异来决定滤波器系数,而是比较分别以两个像素为中心的两个像素块之间的L2范数距离。然后将该距离相对于帧噪声水平进行归一化,该噪声水平也是从源帧估计的,并用于确定滤波器系数。我们的实验证明,在整体压缩性能方面,所提出的非局部均值方法优于[11]和[12]中的先验滤波方法。
II. DENOISING SCHEME IN VIDEO COMPRESSION
针对分层金字塔编码结构,特别设计了降噪方案。接下来我们将讨论视频信号的去噪、时域滤波核及其与编解码器的集成。
A. Noise Removal and Bit Rate Reduction
在视频压缩中,编码过程\((E)\)是首先将源视频信号\(V\)分解为重构表示和残差信号\(R\),然后将\(V\)转换为码流的过程。在有损压缩中,剩余信号在量化阶段被丢弃。设\(rate(·)\)表示比特流中组件的比特率。编码器设置速率\((R)=0\)。
现在考虑源视频信号\(V\)被噪声\(N\)损坏,设\(V^*\)表示真实信号(无噪声)。由于量化过程是编码过程引入的伪影,量化步长是量化噪声的唯一确定因素,我们假设量化噪声\(R\)与源视频信号生成过程中由于物理条件引入的噪声\(N\)无关。源信号可以写成:
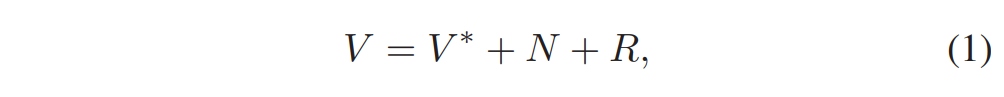
编码过程变成:
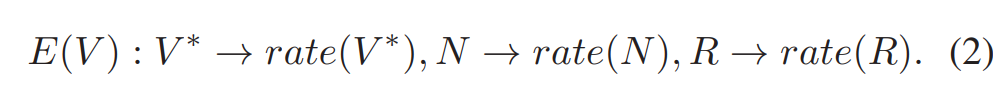
在这个模型中,编码器在压缩过程中保留了真实信号声\(V^*\)加上噪声声\(N\)。然而,噪声是不需要的信息,它降低了视觉质量(除了故意添加噪声的情况,如膜粒噪声),衰减了重构帧之间的时间一致性,最终降低了压缩效率。因此需要降低声\(rate(N)\),或者理想情况下设置声\(rate(N)=0\)。
B. Video Denoising in Hierarchical Coding Structure
去除噪声并不一定能提高视频编码的压缩效率。去除噪声信号不可避免地会降低客观指标(例如,PSNR),因为指标是根据源视频信号计算的。
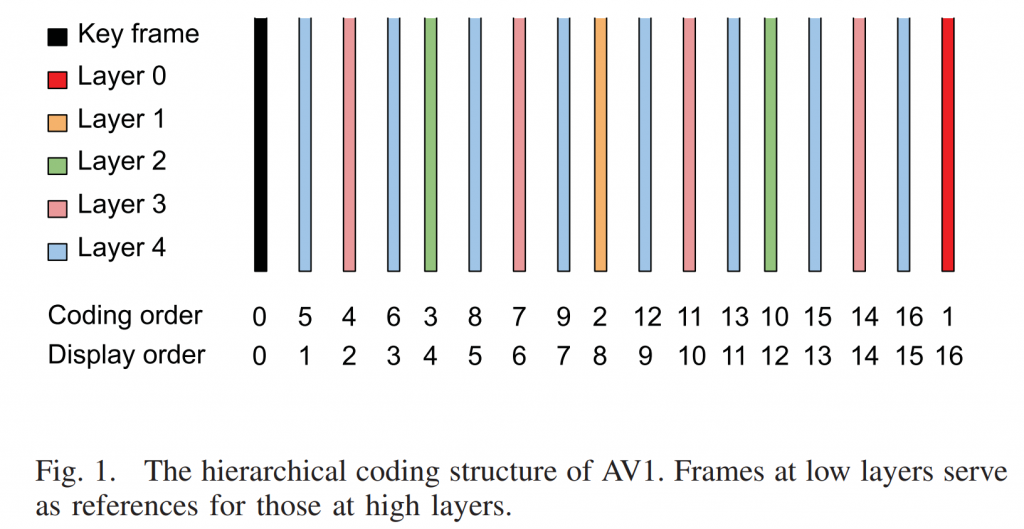
我们的解决方案是只对分层编码结构中的关键帧和0层帧进行去噪。在AV1中,每组图片(GOP)的层次结构有固定的长度,如图1所示。分层编码结构最重要的特点是不同层的比特率分配。视频信号按照金字塔结构无序编码,其中底层帧以较高的比特率预算编码,并作为上层帧的参考帧。该方案显著提高了编码效率。在AV1中,关键帧和0层帧占用比特率预算的百分比最大。图2显示了不同层的平均编码帧大小示例,其中包括mobile_cif和highway_cif的示例剪辑。
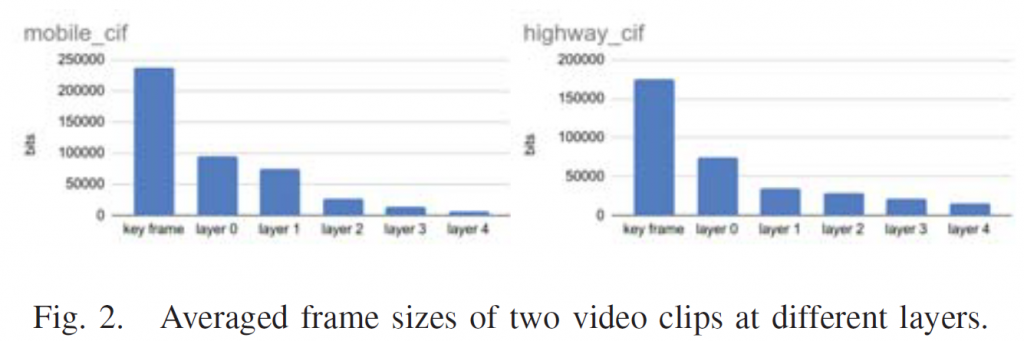
我们的实验表明,朴素的均匀视频去噪(在每个帧上不加区别地应用去噪)并不能提高AV1的压缩性能。原因是高层帧的比特率预算太小,无法在比特率降低和PSNR降低之间进行权衡。只有关键帧和层0处的帧具有显著比特率节省的潜力。
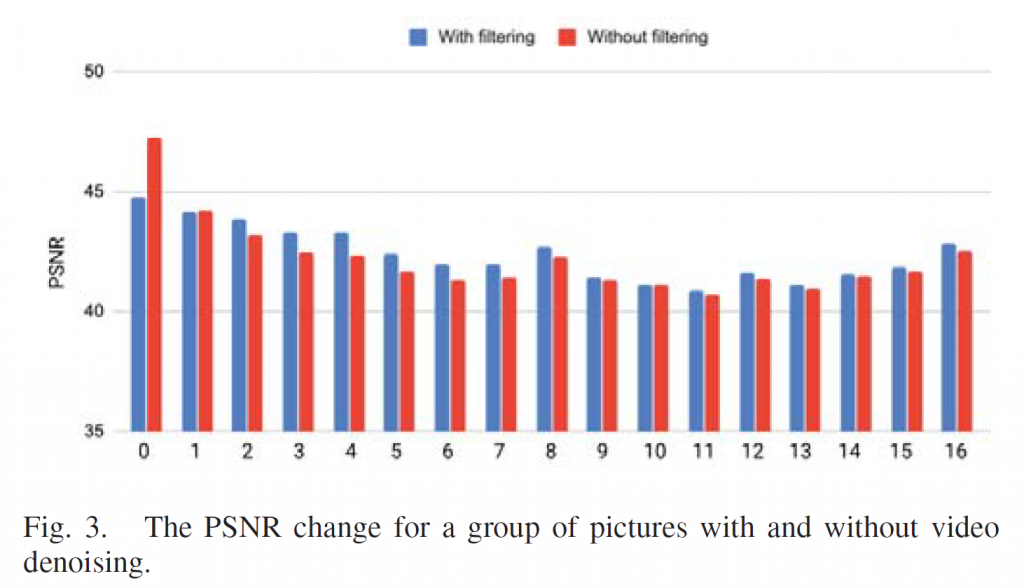
去噪的效果如图3所示的例子所示。在本例中,对150帧进行编码,并显示第一个GOP的PSNR值。我们观察到,去噪后,虽然关键帧的PSNR值下降了约2 dB,但后续帧的PSNR值增加了。这是因为去噪后的关键帧对接下来的帧有更好的参考作用,导致该GOP的PSNR增加。同时,实现了关键帧上比特率预算的减少。因此,整体压缩性能得到显著提高。
C. GOP Based Temporal Filter for HEVC
Wennersten等人[12]提出了一种基于gops的HEVC时间滤波器。它对第0层和第1层的帧进行过滤。对待过滤帧前后的帧进行运动补偿,寻找最佳匹配样本。滤波器系数取决于样本之间的差异,以及量化参数(QP)。滤波后的样本值\(f(i)\)由下式计算:
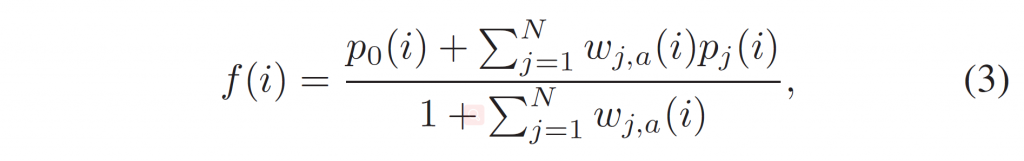
其中,\(p_j(i)\)是第j个运动补偿帧的采样值,\(p_0(i)\)为当前帧的样本值,\(w_{j,a}(i)\)表示可用帧数为\(a\)时第\(j\)个移动补偿帧的权重。\(N\)是候选帧数。对于亮度通道,权重\(w_{j,a}(i)\)定义为:
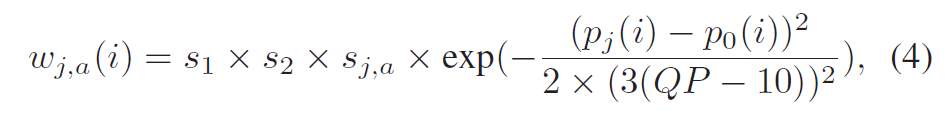
如果当前poc是16的倍数,则\(s1=1.5\),否则\(s1=0.95\);\(s2=0.4. \)s_{j,a}[/latex]确定为:
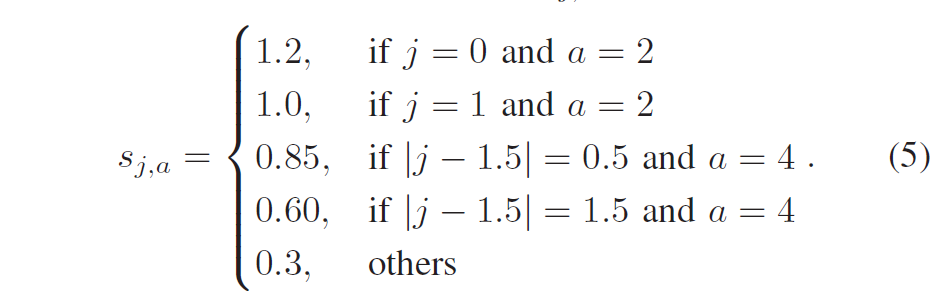
对于色度通道,权重\(w_{j,a}(i)\)定义为:
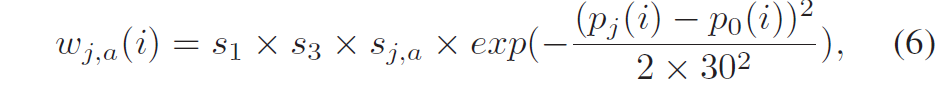
其中\(s3=0.55\)。
D. Non-local Mean Temporal Filtering Scheme
在本节中,我们提出了AV1的非局部时间滤波方案。与第II-C节中描述的滤波器相比,我们强调了两个主要因素:使用(1)patch difference和(2)noise level自适应确定滤波器系数。
与已有工作类似,我们的方法将当前帧划分为M × M块。对于每个块,运动搜索应用于当前帧之前和之后的帧。只有具有最小均方误差(MSE)的最佳匹配patch才被保留为邻居帧的候选patch。当前块也是一个候选patch。将N个候选patch组合在一起生成过滤后的输出。
设\(f(i)\)为过滤后的样本值,\(p_j (i)\)为第\(j\)个patch的样本值。过滤过程为:
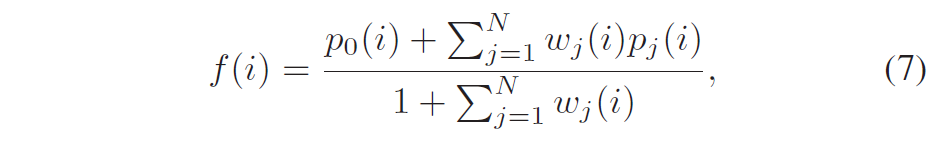
其中\(w_j(i)\)是总共N个patch中的第\(j\)个patch的权重。
与第II-C节描述的滤波器不同,我们采用基于patch的差异而不是样本对样本的差异来确定滤波器系数。基于patch的差分的优点是它不会引入系统噪声[6],这是去噪的理想属性。权重由patch差确定为:
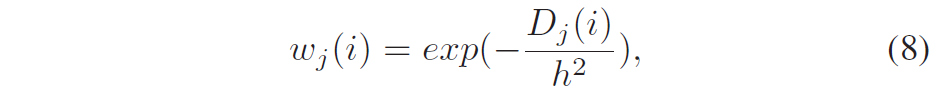
其中,\(D_j(i)\)为当前块与第\(j\)个候选补丁之间的差的平方和:
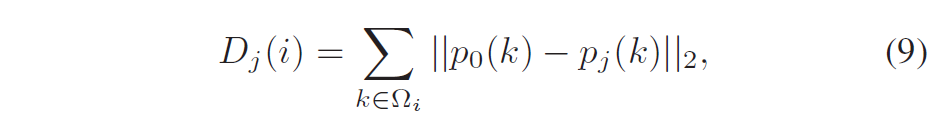
其中\(p_0\)指当前帧,\(Ω_i\)是补丁窗口,一个L×L正方形。\(h\)是控制由欧氏距离测量的权值衰减的关键参数。
基于补丁的算法参数的选取问题引起了人们的研究兴趣。\(h\)的大小对滤波系数有显著影响。一般情况下,在补丁差不变的情况下,\(h\)的增加会导致除当前帧外的参考补丁的权重更高,表明时间滤波更强。在我们的应用中,\(h\)由声源的噪声水平决定,这样滤波器系数适用于不同噪声的视频。设\(σ\)表示噪声的标准差,我们将\(h\)表示为相对于\(σ\)的单调递增因子:
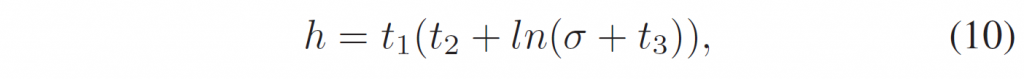
其中\(t1 = 4\), \(t2 = 0.7\), \(t3 = 0.5\),这是实验确定的。通过这种方式,当视频被更高的噪声破坏时,应用了更强的平滑。
值得一提的是,我们发现,将\(h\)表述为\(σ\)的平稳增长函数提供了比我们之前在[14]中的工作更好的压缩性能,在[14]中,我们假设存在一个中心噪声水平,大多数视频的噪声都处于一个小范围内,从而得出\(h = C × exp(1 – σ) × σ\)。这样的公式适用于许多视频,但当我们在一个大的视频数据集上进行测试时,这个假设就不成立了,因为任何噪声级别都可能出现。
III. EXPERIMENTAL RESULTS
提出的时间滤波在libaom AV1框架[15]中实现。我们还在[12]中实现了基于gop的时间滤波器进行比较。注意,在[12]中,只使用当前帧前后的两个帧进行过滤,而在提议的方法中使用了三个帧。因此,参数\(s_{j,a}总是设置为0.3。这两种过滤器只应用于关键帧和0层帧,块大小[latex]M = 32\),窗口大小\(L = 5\),总共\(N = 7\)参考帧。参数\(σ\)由当前帧用[16]估计。
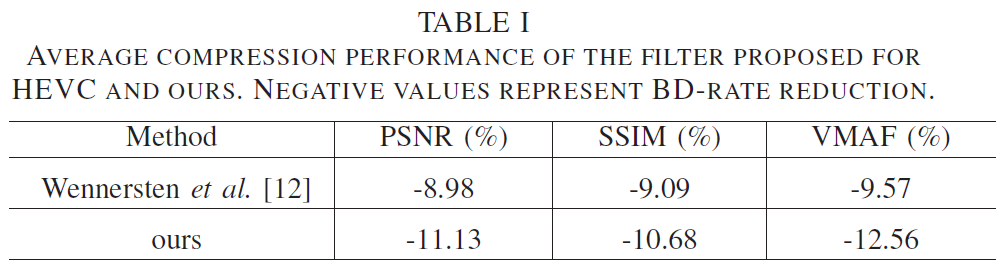
我们评估了720p和1080p视频的压缩性能,speed 1 (-cpu-used =1),在恒定质量模式下(-end-usage =q),最大帧数为150。压缩效率的提高分别通过PSNR、SSIM和VMAF的BD率降低来衡量。负值表示更好的编码性能。
表i显示了[12]和我们提出的滤波器相对于没有时间滤波的基线的平均性能。两种滤波器都显著提高了编码效率。提出的非局部均值滤波器在[12]上的相对编码性能如表II所示。显然,使用基于批处理的距离和噪声水平感知的核估计有一定的编码优势。
仔细观察单个视频片段的编码性能可以发现,编码增益较大的视频片段都是噪声水平相对较高的视频片段,如vidyo1_720p60, vidyo3_720p60。对于噪音水平非常低的视频,我们的方法可能会提供边际性能增益,如屏幕内容视频:life 1080p30。
图4显示了一个可视化示例。绘制了源图像和使用[12](中间行)中的滤波器和我们的滤波器(最后一行)的滤波图像之间的Y、U、V通道差异。从Y通道的差分图像中,我们观察到我们的滤波器比现有滤波器去除的结构信息更少。从U通道和V通道的差分图像中,我们可以看到我们的滤波器比其他滤波器更好地捕捉到源图像中呈现的强噪声。

IV. CONCLUSION AND FUTURE WORK
在这项工作中,我们提出了一个非局部平均时间滤波方案的视频压缩。对分层编码结构中的关键帧和底层帧进行滤波。滤波器系数的设计既考虑了贴片差又考虑了噪声水平。实验表明,它优于其他用于libvpx VP8, VP9和HEVC HM编码器的时间滤波器。
REFERENCES
[1] Eric Dubois and Shaker Sabri. Noise reduction in image sequences
using motion-compensated temporal filtering. IEEE Transactions on
Communications, 32(7):826–831, 1984.
[2] Jill M Boyce. Noise reduction of image sequences using adaptive
motion compensated frame averaging. In In 1992 IEEE International
Conference on Acoustics, Speech, and Signal Processing, volume 3,
pages 461–464. IEEE, 1992.
[3] Yaowu Xu. Inside webm technology: The vp8 alternate reference
frame. http://blog.webmproject.org/2010/05/inside-webm-technologyvp8-alternate.html, 2010.
[4] Eugen Wige, Peter Amon, Andreas Hutter, and Andre Kaup. In- ´
loop denoising of reference frames for lossless coding of noisy image
sequences. In 2010 IEEE International Conference on Image Processing,
pages 461–464. IEEE, 2010.
[5] Eugen Wige, Gilbert Yammine, Wolfgang Schnurrer, and Andre Kaup. ´
Mode adaptive reference frame denoising for high fidelity compression
in hevc. In 2012 Visual Communications and Image Processing, pages
1–6. IEEE, 2012.
[6] Antoni Buades, Bartomeu Coll, and J-M Morel. A non-local algorithm
for image denoising. In 2005 IEEE Computer Society Conference on
Computer Vision and Pattern Recognition (CVPR’05), volume 2, pages
60–65. IEEE, 2005.
[7] Kostadin Dabov, Alessandro Foi, Vladimir Katkovnik, and Karen
Egiazarian. Image denoising by sparse 3-d transform-domain collaborative filtering. IEEE Transactions on Image Processing, 16(8):2080–
2095, 2007.
[8] Eugen Wige, Gilbert Yammine, Peter Amon, Andreas Hutter, and
Andre Kaup. Efficient coding of video sequences by non-local in- ´
loop denoising of reference frames. In 2011 18th IEEE International
Conference on Image Processing, pages 1209–1212. IEEE, 2011.
[9] Kostadin Dabov, Alessandro Foi, and Karen Egiazarian. Video denoising
by sparse 3d transform-domain collaborative filtering. In 2007 15th
European Signal Processing Conference, pages 145–149. IEEE, 2007.
[10] Matteo Maggioni, Giacomo Boracchi, Alessandro Foi, and Karen
Egiazarian. Video denoising, deblocking, and enhancement through
separable 4-d nonlocal spatiotemporal transforms. IEEE Transactions
on image processing, 21(9):3952–3966, 2012.
[11] The WebM Project. https://chromium-review.googlesource.com.
[12] P. Wennersten. Encoder-only gop-based temporal filter. ITU-T SG 16
WP 3 and ISO/IEC JTC 1/SC 29/WG 11, Document: JCTVC-AI0023-
v2, 2019.
[13] Joseph Salmon. On two parameters for denoising with non-local means.
IEEE Signal Processing Letters, 17(3):269–272, 2009.
[14] Cheng Chen, Jingning Han, and Yaowu Xu. Video denoising for the
hierarchical coding structure in video coding. IEEE Sigport, 2020.
[15] Alliance for Open Media. https://aomedia.googlesource.com/aom/.
[16] Shen-Chuan Tai and Shih-Ming Yang. A fast method for image noise
estimation using laplacian operator and adaptive edge detection. In 2008
3rd International Symposium on Communications, Control and Signal
Processing, pages 1077–1081. IEEE, 2008.