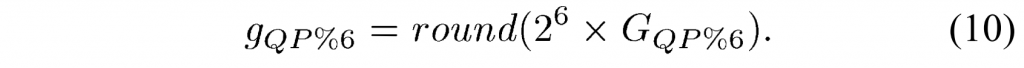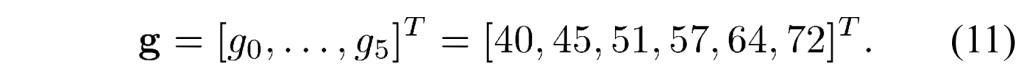POSIX多线程程序设计. 作者 美 David R.Buten
大部分多线程程序需要在线程间共享数据。如果两个线程同时访问共享数据就可能会有问题,因为一个线程可能在另一个线程修改共享数据的过程中使用该数据,并认为共享数据保持未变。
使线程同步最通用和常用的方法就是确保对相同(或相关)数据的内存访问”互斥地”进行,即一次只能允许一个线程写数据,其他线程必须等待。Pthreads使用了一种特殊形式的信号灯——互斥量。互斥量(mutex)是由单词互相(mutual)的首部”mut”和排斥(eexclusion)的首部”ex”组合而成的。
同步不仅仅在修改数据时重要,当线程需要读取其他线程写入的数据时,而且数据写入的顺序也有影响时,同样需要同步。
考虑以下实例:一个线程向数组中某个元素填加新数据,并更新max_index变量以表明该数组元素有效。在另一个处理器上同时运行的处理线程,负责遍历数组并处理每个有效元素。如果处理线程在读取数组元素的新数据:之前先读取了更新后的max_index值,计算就会出错。这可能显得有些不太合理,但是以这种方式工作的内存系统比按照确定顺序访问内存的系统要快得多。互斤量是解决此类问题的通用方法:在访问共享数据的代码段周围加锁互斥量,则一次只能有一个线程进入该代码段。
下图显示了共享互斥量的三个线程的时序图。处于标有”互斥量”的圆形框之上的线段表示相关的线程没有拥有互斥量。处于圆形框中心线之下的线段表示相关的线程拥有互斥量。处于中心线之上的线段表明相关的线程等待拥有互斥量。
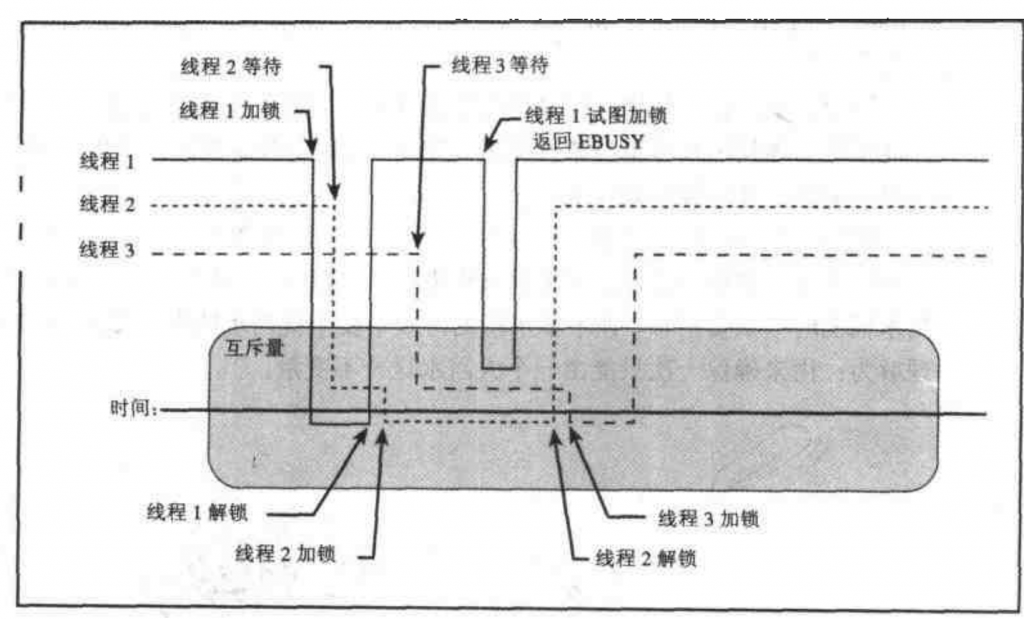
最初,互斥量没有被加锁。当线程1试图加锁该互斥量时,由于于没有竞争,线程1立即加锁成功,对应线段也移到中心线之下。然后线程2试图加锁互斥量,由于互斥量已经被锁住,所以线程2被阻塞,对应线段在中心线之上。线程1解锁互斥量,解除线程2的阻塞,使其对互斥量加锁成功。稍后,线程3试图加锁互斥量被阻塞。线程1调用函数pthread_mutex_trylock试着锁住互斥量,而立刻返回EBUSY。线程2解锁互斥量,解除线程3的阻塞,线程3加锁成功。最后,线程3完成工作,解锁互斥量。
1 创建和销毁互斥量
pthread_mutex_t_mutex = PTHREAD_MUTEX_INITTALIZER;
int pthread nutex init(
pthread_mutex_t *mutex, pthread_mutexattr_t*attr);
int Pthread_mutex_destroy (Pthread_mutex_t*mutex);
程序中的互斥量是用pthread_mutex_t类型的变量来表示的。不能拷贝互斥量变量,因为使用拷贝的互斥量是不确定的。可以拷贝指向互斥量的指针,这样就可以使多个函数或线程共享互斥量来实现同步。
大部分时间你可能在”文件范围”内,即函数体外,声明互斥量为外部或静态存储类型。如果有其他文件使用互斥量,则将其声明为外部类型;如果仅在本文件内使用,则将其声明为静态类型。你应该使用宏 PTHREAD_MUTEEX_INITIALIZER 来声明具有默认属性的静态互斥量,如下面例程mutex_staltic.c所示(你可以编译并运行该程序,不过因为main函数为空,所以不会有任何结果)。
#include <pthread.h>
#include "errors,h"
/*
* Declare a structure, with a mutex, statically initialized. This
* is the same as using pthread_mutex_init, withthe default,
* attributes.
*/
typedef struct my_struct_tag {
pthread_mutex_t mutex; /* Protects access to value */
int value; /* Access protected by mutex */
} my_struct_t;
my_struct_t data = {PTHREAD_MUTEX_INITIALIZER, 0};
int main (int argc, char *argv[])
{
return 0;
}
通常不能静态地初始化一个互斥量,例如当使用malloc动态分配一个包含互斥量的数据结构时。这时,应该使用pthread_mutex_init调用来动态地初始化互斥量,如下面程序mutex_dynamic.c所示。也可以动态地初始化静态声明的互斥量,但必须保证每个互斥量在使用前被初始化,而且只被始化一次。可以在创建任何线程之前初始化它,如通过调用pthread_once。如果需要初始化一个非缺省属性的互斥量,必须使用动态初始化。
#include <pthread.h>
#include "errors.h"
/*
* Define a structure, with a mutex.
*/
typedef struct my_struct_tag {
pthread_mutex_t mutex; /* Protects access to value */
int value; /* Access protected by mutex */
} my_struct_t;
int main (int argc, char *argv[]) {
my_struct_t *data;
int status;
data = malloc (sizeof (my_struct_t));
if (data == NULL)
errno_abort ("Allocate structure");
status = pthread_mutex_init (&data->mutex, NULL);
if (status != 0)
err abort (status, "Init mutex");
status = pthread_mutex_destroy (&data->mutex);
if (status != 0)
err_abort (status, "Destroy mutex");
(void)free (data);
return status;
}将互斥量与它要保护的数据明显地联系起来是个不错的注意。如果可能的话,将互斥量和数据定义在一起。例如,在mutex_static.c和mutex_dynamic.c中,互斥量和它要保护的数据就被定义在同一个数据结构中,并通过注释语句记录了这种关系。
当不再需要一个通过pthread_mutex_init调用动态初始化的互斥量时,应该调用pthread_mutex_destroy来释放它。不需要释放一个使用
PTHREAD_MUTEX_INITIALIZER 宏静态初始化的互斥量。当确信没有线程在互斥量上阻塞时,可以立刻释放它。
当知道没有线程在互斥量上阻塞,且互斥量也没有被锁住时,可以安全地释放它。获知此信息的最好方式是在刚刚解锁互斥量的线程内,程序逻辑确保随后不再有线程会加锁该互斥量。当线程在某个堆栈数据结构中锁住互斥量,以从列表中删除该结构并释放内存时,在释放互斥量占有的空间之前先将互斥量解锁和释放是个安全且不错的主意。
2 加锁和解锁互斥量
int pthread_mutex_lock (pthread_mutex_t *mutex)
int pthread_mutex_trylock (pthread_mutex_t *mutex)
int pthread_mutex_unlock (Pthread_mutex_t *mutex)在最简单的情况下,使用互斥量是容易的事情。通过调用pthread_mutex_lock或pthread_mutex_trylock锁住互斥量,处理共享数据,然后调用pthread_mutex_unlock解锁互斥量。为确保线程能够读取一组变量的一致的值,需要在任何读写这些变量的代码段周围锁住互斥量。
当调用线程已经锁住互斥量之后,就不能再加锁该互斥量。试图这样做的结果可能是返回错误(EDEADLK),或者可能陷入”自死锁”,使不幸的线程永远等待下去。不能解锁一个已经解锁的互斥量,也不能解锁由其他线程锁住的互斥量。锁住的互斥量是属于加锁线程的。
下面程序alarm_mutex.c是alarm_thread.c的改进版本。它在一个alarmserver线程中处理多个闹铃的请求。
结构体alarm_t现在包含了一个标准UNIX time_t类型的绝对时间,表示从UNIX纪元(1970年1月1日00:00)开始到闹铃时的秒数。这样alarm_t结构体就可以按照闹铃时间排序,而不是按照请求的秒数排序。另外,还有一个link元素将所有请求链接起来。
互斥量alarm_mutex负责协调对闹铃请求列表alarm_list的头节点的访问。互斥量是使用默认属性调用宏 PTHREAD_MUTEX_INITIALIZER 静态初始化的。列首指针初始化为空。
#include <pthread.h>
#include <time.h>
#include "errors.h"
/*
* The "alarm" structure now contains the tinme t (time since the
* Epoch, in seconds) for each alarm, so thatthey can be
* sorted. Storing the requested number of sedconds would not be
* enough, since the "alarm thread" cannot tel11 how long it has
* been on the list.
*/
typedef struct alarm_tag {
struct alarm_tag *link;
int seconds;
time_t time; /* seconds from EPOCH */
char message[64];
} alarm_t;
pthread_mutex_t alarm_mutex = PTHREAD_MUTEX_INITIALIZER;
alarm_t *alarm_list = NULL;
下面讲述函数alarm_thread的代码。该函数作为线程运行,并依次处理列表alarm_list中的每个闹铃请求。线程永不停止,当main函数返回时,线程”蒸发”。这种做法的惟一后果是任何剩余请求都不会被传送,线程没有保留任何能够在进程之外可见的状态。
如果希望程序在退出之前处理所有未完结的闹铃请求,可以简简单地修改程序以达到该目标。当主线程发现列表 alarm_list为空时,需要通过某种方式通知alarm_thread线程终止。例如,可以在主线程中设置一个全局变量alarm_done的值,然后调用pthread_exit而不是调用exit终止。当alarm_thread线程发现列表为空且alarm_done被置位时,它会立即调用pthread_exit,而不是等待下一个请求。
如果列表中没有新的请求,alarm_thread线程需要阻塞自己一小段时间,解锁互斥量,以便主线程能够添加新的闹铃请求。通过将sleep_time置为1秒来作到这点。
如果列表中发现请求,则将它从列表中删除。调用time函数放获得当前时间,并将其与请求时间比较。如果闹铃时间已经过期,则alarm_thread线程将sleep_time置为0;否则,alarm_thread线程计算闹铃时间与当前时间的差,并将sleep_time置为该差值(以秒为单位)。
在线程睡眠或阻塞之前,总是要解锁互斥量。如果互斥量仍被锁住,则主线程就无法向列表中增加请求。这将使程序变成同步工作方式,因为用户必须等到闹铃之后才能做其他事(用户可能输入一个命令,但是必须等到下一闹钟到期时才能获得系统提示)。调用sleep将阻塞alarm_thread线程指定的时间,直到经过该时间后线程才能运行。
调用sched_yield的效果果是将处理器交给另一个等待运行的线程,但是如果没有就绪的线程,则立即返回。在程序中,调用sched_yield意味着:如果有等待处理的用户输入,则主线程运行,处理用户请求;如果用户没有输入请求,则该函数立即返回。
如果alam指针非空,即如果已经从alarm_list列表中处理里了一个闹铃请求,则函数打印消息显示闹铃已到期。然后,线程释放alarm结构,准备处理下一个闹铃请求。
/*
* The alarm thread's start routine.
*/
void *alarm_thread (void *arg) {
alarm t *alarm;
int sleep time;
time t_now;
int status;
/*
* Loop forever, processing commands. The alarmthread will
* be disintegrated when the process exits.
*/
while (1) {
status = pthread_mutex_lock (&alarm_mutex);
if (status != 0)
err_abort (status, "Lock mutex");
alarm = alarm_list;
/*
* If the alarm list is empty, wait for one second. This
* allows the main thread to run, and readanother
* command. If the list is not empty, remove tthe first
* item. Compute the number of seconds to wait-- if the
* result is less than 0 (the time has passed), t!hen set
* the sleep time to 0.
*/
if (alarm == NULL)
sleep_time = 1;
else {
alarm_lişt = alarm->link;
now = time (NULL);
if (alarm->time <= now)
sleep_time = 0;
else
sleep_time = alarm->time - now;
#ifdef DEBUG
printf ("[waiting: %d(%d)\"Bs\"]\n", alarm->timne,
sleep time, alarm->message);
#endif
}
/*
* Unlock the mutex before waiting, so that thhe main
* thread can lock it to insert a new alarm request.If
* the sleep_time is 0, then call sched yield, giving9
* /the main thread a chance to run if it has been n
* readied by user input, without delaying the message
* if there's no input.
*/
status = pthread_mutex_unlock (salarm_mutex);
if (status != 0)
err_abort (status, "Unlock mutex");
if (sleep_time > 0)
sleep (sleep_time);
else
sched_yield ();
/*
* If a timer expired, print the message and free the
* structure.
*/
if (alarm != NULL) {
printf("(td) ts\n", alarm->seconds, alarm->me(ssage)
free (alarm);
}
}
}最后,我们来讨论alarm_mutex.c的主程序代码。基本结构我们已经开发过的版本相同,包括一个循环、从stdin中读取用户输入的请求并依次处理它们。这一次,没有像alarm.c中那样同步地等待,也没有像alarm_fork.c 或alarm_thread.c 那样为每个请求创建一个异步处理实体进程或线程),而是将所有请求排队,等待服务线程alarm_thread处理。一旦主线程将所有请求排队,它就可以读取下一个请求了。
建立一个服务线程来处理所有请求。返回的线程ID保存在局部变量thread中(尽管我们不使用它)。
与其他的闹铃版本一样读取并处理用户请求。就像在alarm_thread.c中那样,数据保存在malloc分配的堆结构中。
程序将闹铃请求添加到alarm_list列表中,该列表由主线程和alarm_thread线程共享。所以在访问共享数据之前,需要将互斥量alarm_mutex加锁。
由于线程alarm_thread串行地处理列表中的请求,所以没有办法知道从读取用户请求到处理请求的时间间隔。因此,alarm结构中包含了闹铃的绝对时间。绝对时间是通过将用户输入的闹铃时间间隔加上由time调用返回的当前时间获得。
闹铃请求在列表alarm_list中按照闹铃时间先后顺序排序。插入代码遍历列表,直到找到第一个闹铃时间大于或等于新闹铃请求时间的节点,然后将新请求插入到找到的节点前。因为alarm_list是个简单的链表,遍历维护了两个指针:一个next指针指向当前节点,一个last指针指向前一个节点的link指针或者指向列表头指针。
如果没有找到大于或等于当前闹铃时间的节点,则将新请求节点插入列表尾部。当退出遍历时,如果当前节点指针为NULL,则前一节点(或链表头)指向新请求节点。
int main (int argc, char *argv[]) {
int status;
char line[128];
alarm_t *alarm, **last, *next;
pthread_t thread;
status = pthread_create {
&thread, NULL, alarm_thread, NULL);
if (status != 0)
err_abort (status, "Create alarm thread");
while {1) {
printf ("alarm> ");
if(fgets(line, sizeof(line), stdin) == NULL) exit(0)
if (strlen (line)<= 1) continue;
alarm = (alarm_t*)malloc (sizeof (alarm_t));
if (alarm == NULL)
errno_abort ("Allocate alarm");
/*
* Parse input line into seconds (%d) and a message
* (864[^\n]), consisting of up to 64 charadters
* separated from the seconds by whitespace.
*/
if (sscanf (line, "%d 864[^\n]",
&alarm->seconds, alarm->message) < 2) {
fprintf (stderr, "Bad command\n");
free (alarm);
} else {
status = pthread_mutex_lock (&alarm_mutex);
if (status != 0)
err_abort (status, "Lock mutex");
alarm->time = time (NULL) + alarm->seconds;
/*
* Insert the new alarm into the list of alarmis,
* sorted by expiration time.
*/
last = &alarm_list;
next = *last;
while (next!= NULL) {
if (next->time >= alarm->time) {
alarm->link = next;
*last = alarm;
break;
}
last = &next->link;
next = next->link;
}
/*
* If we reached the end of the list, insert tthe new
* alarm there. ("next" is NULL, and "last" pointts
* to the link field of the last item, or tothe
* list header).
*/
if (next == NULL){
*last = alarm;
alarm->link = NULL;
}
#ifdef DEBUG
printf ("[list: ");
for (next = alarm_list; next != NULL; next = 1next->link)
printf ("#d{%d)[\'\'\'] ", next->time,
next->time - time (NULL), next->message);
printf ("]\n");
#endif
status = pthread_mutex_unlock (&alarm_mutex);
if (status 1= 0)
err_abort (status, "Unlock mutex");
}
}
}这个简单的例子存在几个严重的缺点。尽管与alarm_fork.c 和 alarm_thread.c相比,该实例具有占用更少资源的优势,但它的响应性能不够。一旦alarm_thread线程从列表中接收了一个闹铃请求,它就进入睡眠直到闹铃到期。当它发现列表中没有闹铃请求时,也会睡眠1秒,以允许主线程接收新的用户请求。当alarm_thread线程睡眠时,它就不能注意到由主线程添加到请求列表中的任何闹铃请求,直到它从睡眠中返回。
这个问题可以通过不同的方式解决。当然最简单的为方式就是像alarm_thread.c那样为每个闹铃请求建立一个线程。当然这也不坏,因为线程还是比较廉价的。不过还是没有alarm_t数据结构廉价,并且我们更喜欢构造高效的程序,而不仅仅是响应性好的程序。最好的办法是使用条件变量来通知共享数据的状态变化。
3 非阻塞式互斥量锁
当调用pthread_mutex_lock加锁互斥量时,如果此时互斥量已经被锁住,则调用线程将被阻塞。通常这是你希望的结果,但有时你可能希望如果互斥量已被锁住,则执行另外的代码路线,你的程序可能做其他一些有益的工作而不仅仅是等待。为此,Pthreads提供了pthread_mutex_trylock函数,当调用互斥量已被锁住时调用该函数将返回错误代码EBUSY。
使用非阻塞式互斥量加锁函数时,需要确保只有当pthread_mutex_trylock函数调用成功时,才能解锁互斥量。只有拥有互斥量的线程才能解锁它。一个错误的pthread_mutex_trylock函数调用可能返回错误代码,或者可能解锁其他线程依赖的互斥量,这将导致程序产生难以调试的错误。
4 调整互斥量满足工作
互斥量有多大?我可不是指一个pthread_mutex_t类型的结构构占了多少内存。我是使用了一种通俗的、不完全准确的、但是可以被大多数人接受的说法。这种有趣的用法是在有关如何将非线程代码改为线程安全代码的过程中流行起来的。实现线程安全的函数库的一个相对简单的做法是创建一个互斥量,在每次进入函数库时锁住它,在退出库的时候解锁它,这样函数库就变成了一个串行区域,从而防止了线程问的任何冲突。我们就把保护如此大的串行区域的互斥量称为”大”互斥量,并形而上学地认为比那些只保护几行代码的互斥量要明显地大。
进一步扩展,保护两个变量的互斥量比保护一个变量的互斥量要”大”。那么到底互斥量该多大呢?答案只能是:足够大,但不要太大。
当需要保护两个共享变量时,你有两种基本策略:可以为每个个变量指派一个”小”的互斥量,或者为两个变量指派一个”大”的互斥量。哪一种方法更好取决于很多因素。并且,在开发过程中影响因素可能发生改变,这依赖于有多少线程需要共享数据和如何使用共享变量。
以下是主要的设计因素:
- 互斥量不是免费的,需要时间来加锁和解锁。锁住较少互斥量的程序通常运行得更快。所以,互斥量应该尽量少,够用即可,每个互斥量保护的区域应则尽量大。
- 互斥量的本质是串行执行。如果很多线程需要频繁地加锁同一个互斥量,则线程的大部分时间就会在等待,这对性能是有害的。如果互斥量保护的数据(或代码)包含彼此无关的片段,则可以将大的互斥量分解解为几个小的互斥量来提高性能。这样,任意时刻需要小互斥量的线程减少,线程等待时间就会减少。所以,互斥量应该足够多(到有意义的地步),每个互斥量保护的区域则应尽量的少。
- 上述两方面看似互相矛盾,但是这不是我们头一次遇到的情清况。一旦当你解了互斥量的性能后,就能够正确地处理它们。
在复杂的程序中,通常需要一些经验来获得正确的平衡。在大多数情况下,如果你开始使用较大的互斥量,然后当经验或性能数据告诉你哪个地方存在频繁的竞争时,你应改用较小的互斥量,则你的代码通常会更为简单。简单单是好的。除非发现问题,否则不要轻易花费太多时间优化你的代码。
另一方面,如果从一开始就能明晰你的算法必然导致频繁的竞争,则不要过于简单化。开始使用必须的互斥量和数据结构比后来增加它们容易得多。
5 使用多个互斥量
有时,一个互斥量是不够的,特别是当你的代码需要跨越软件体系内部的界限时。例如,当多个线程同时访问一个队列结构时,你需要两个互斥量,一个用来保护队列头,一个用来保护队列元素内的数据。当为多线程建立一个树型结构时,你可能需要为每个节点设置一个互斥量。
同时使用多个互斥量会导致复杂度的增加。最坏的情况就是死锁的发生,即两个线程分别锁住一个互斥量而等待对方的互斥量。
如果可以在独立的数据上使用两个分离的互斥量,那么就应该这样做。这样,通过减少线程必须等待其他线程完成数据操作(甚至是该线程不需要的数据)的时间,你的程序会最终取得成功。如果数据独立,则某个特定函数就不太可能经常需要同时加锁两个互斥量。
当数据不是完全独立的时候,情况就复杂了。如果你的程序中有一个不变量,影响着由两个互斥量保护的数据,即使该不变量很少被改变或引用,你迟早需要编写同时锁住两个互斥量的代码,来确保不变量的完整。如果一个线程锁住互斥量A后,加锁互斥量B;同时另一个线程锁住互斥量B而等待互斥量A,则你的代码就产生了一个经典的死锁现象。